第十三章:compiler 编译器 - 构建 compile 编译器
01:前言
在上一章我们了解了 compiler 的作用和大致流程之后,那么这一章我们将要在 vue-next-mini 中 实现一个自己的编译器。
但是我们也知道,compiler 是一个非常复杂的概念,我们无法在有限的课程中实现一个完善的编译器,所以,我们将会和之前一样,严格遵循:没有使用就当做不存在 和 最少代码的实现逻辑 这两个标准。只关注 核心 和 当前业务 相关的内容,而忽略其他。
那么明确好了以上内容之后,接下来,就让我们进入编辑器的学习吧~~~
02:扩展知识:JavaScript与有限自动状态机
我们知道想要实现 compiler 第一步是构建 AST 对象。那么想要构建 AST,就需要利用到 有限状态机 的概念。
有限状态机也被叫做 有限自动状态机,表示:有限个状态以及在这些状态之间的转移和动作等行为的数学计算模型
光看概念,可能难以理解,那么下面我们来看一个具体的例子:
根据 packages/compiler-core/src/compile.ts 中的代码可知,ast 对象的生成是通过 baseParse 方法得到的。
而对于 baseParse 方法而言,接收一个 template 作为参数,返回一个 ast 对象。
即:通过 parse 方法,解析 template,得到 ast 对象。 中间解析的过程,就需要使用到 有限自动状态机。
我们来如下模板 (template) :
<div>hello world</div>vue 想要把该模板解析成 AST,那么就需要利用有限自动状态机对该模板进行分析,分析的过程中主要包含了三个特性:
摘自:http://www.ruanyifeng.com/blog/2013/09/finite-state_machine_for_javascript.html
- 状态总数是有限的
- 初始状态
- 标签开始状态
- 标签名称状态
- 文本状态
- 结束标签状态
- 结束标签名称状态
- …
- 任一时刻,只处在一种状态之中
- 某种条件下,会从一种状态转变到另一种状态
- 比如:从
1到2意味着从初始状态切换到了标签开始状态
如下图所示:
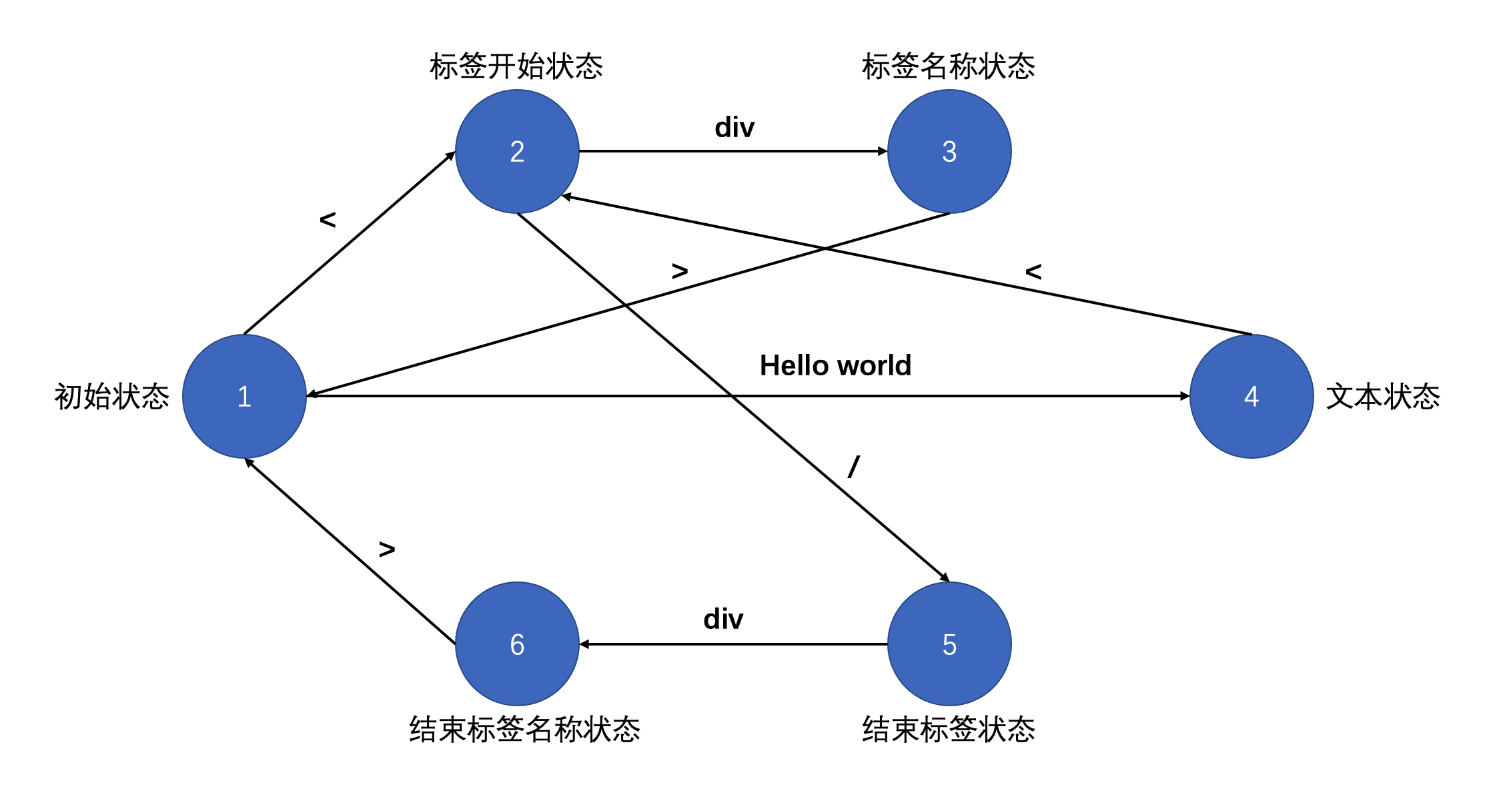
- 解析
<:由 初始状态 进入 标签开始状态 - 解析
div:由 标签开始状态 进入 标签名称状态 - 解析
>:由 标签名称状态 进入 初始状态 - 解析
hello world:由 初始状态 进入 文本状态 - 解析
<:由 文本状态 进入 标签开始状态 - 解析
/:由 标签开始状态 进入 结束标签状态 - 解析
div:由 结束标签状态 进入 结束标签名称状态 - 解析
>:由 结束标签名称状态 进入 初始状态
经过这样一些列的解析,对于:
<div>hello world</div>而言,我们将得到三个 token:
开始标签:<div>
文本节点:hello world
结束标签:</div>而这样一个利用有限自动状态机的状态迁移,来获取 tokens 的过程,可以叫做:对模板的标记化。
总结
那么这一小节,我们了解了什么是有限自动状态机,也知道了它的三个特性。
vue 利用它来实现了对模板的标记化,得到了对应的 token。
那么这些 token 有什么用呢?我们下一小节再说。
03:扩展知识:扫描 tokens 构建 AST 结构的方案
在上一小节中,我们已经知道可以通过自动状态机解析模板为 tokens,那么解析出来的 tokens 就是生成 AST 的关键。
生成 AST 的过程,就是 tokens 扫描的过程。
我们以以下 html 结构为例:
<div>
<p>hello</p>
<p>world</p>
</div>该 html 可以被解析为如下 tokens:
开始标签:<div>
开始标签:<p>
文本节点:hello
结束标签:</p>
开始标签:<p>
文本节点:world
结束标签:</p>
结束标签:</div>具体的扫描过程为(文档中仅显示初始状态和结束状态,具体扫描流程可以查看 课程资料 PPT 第 7 页):
初始状态:
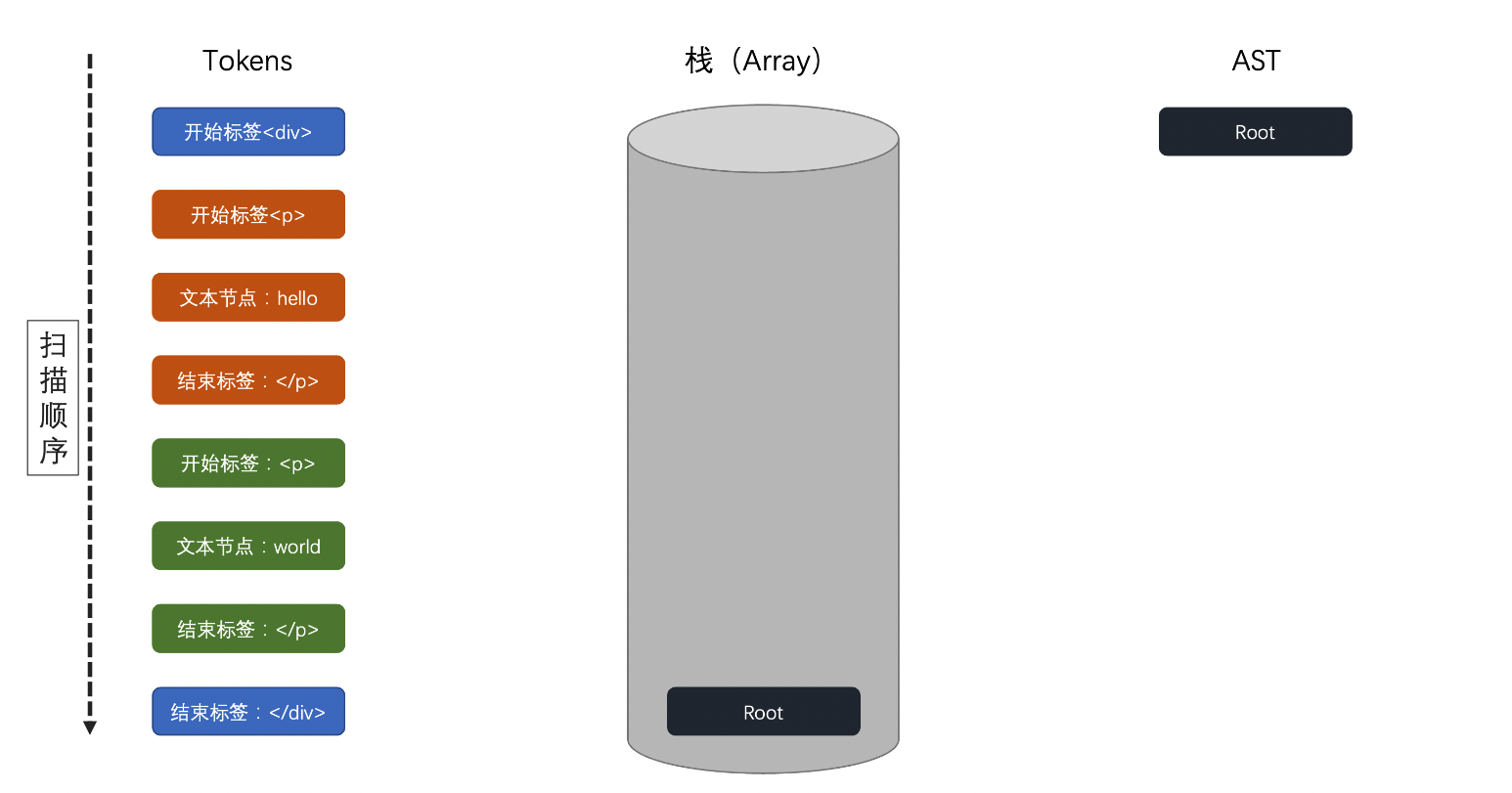
结束状态:
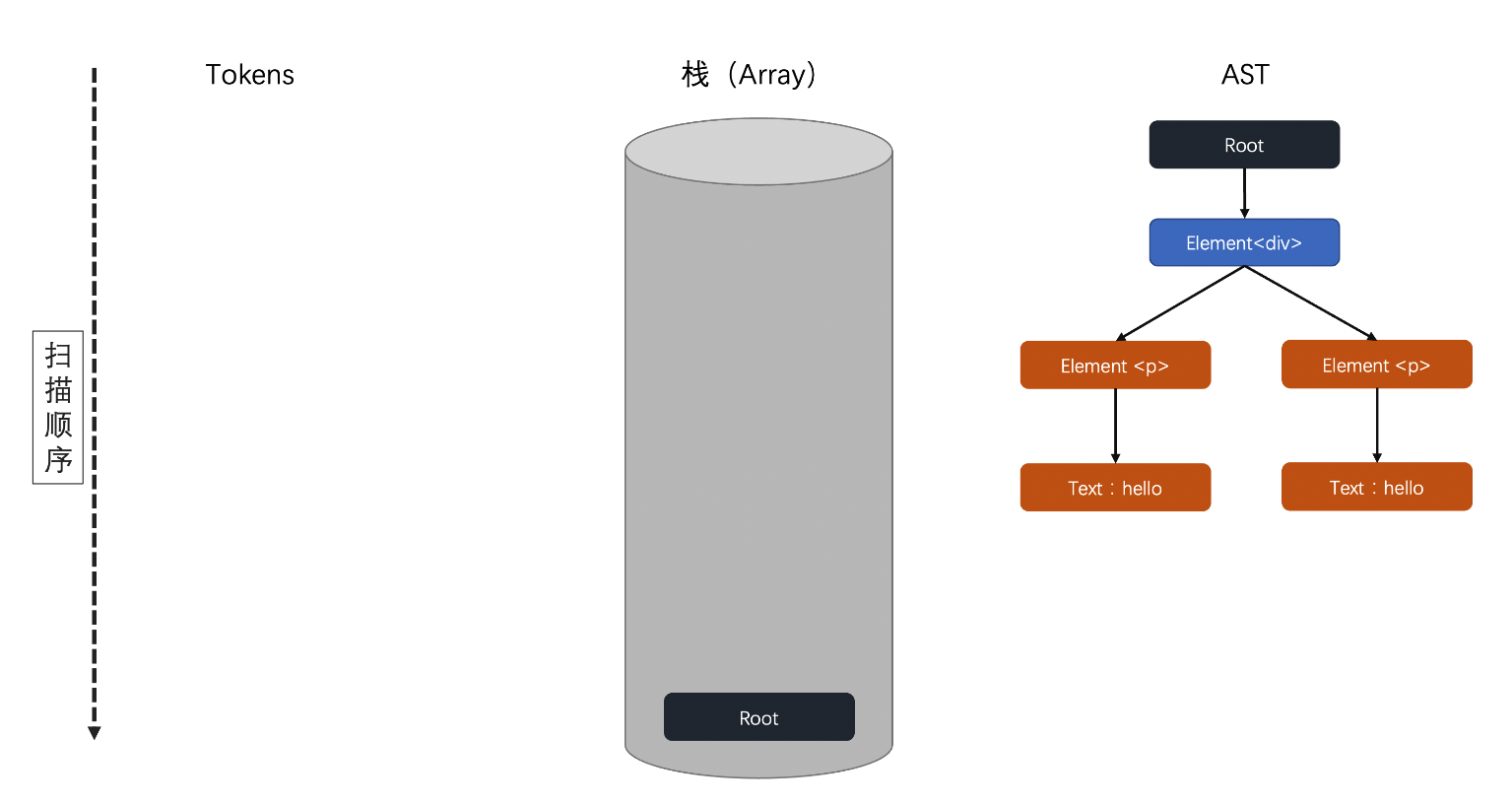
在刚才的图示中,我们通过 递归下降算法? 这样的一种扫描形式把 tokens 通过 栈 解析成了 AST(抽象语法树)。
04:源码阅读:编译器第一步:依据模板,生成 AST 抽象语法树
那么这一小节我们就来看一下 vue 中生成 AST 的代码。该部分代码全部被放入到了 packages/compiler-core/src/parse.ts 中,从这个文件可以看出,整体 parse 的逻辑非常复杂,整体文件有 1173 行代码。
所以我们再去看这一块逻辑的时候,同样会按照之前的方式,只去关注当前业务下的逻辑,而忽略其他逻辑,依次来降低整体的复杂度。
通过 packages/compiler-core/src/compile.ts 中的 baseCompile 方法可以知道,整个 parse 的过程是从 baseParse 开始的,所以我们可以直接从这个方法开始进行 debugger。
测试实例为:
<script>
const { compile, h, render } = Vue
// 创建 template
const template = `<div>hello world</div>`
// 生成 render 函数
const renderFn = compile(template)
</script>当前的 template 对应的目标极简 AST 为(这意味着我们将不再关注其他的属性生成):
const ast = {
"type": 0,
"children": [
{
"type": 1,
"tag": "div",
"tagType": 0,
// 属性,目前我们没有做任何处理。但是需要添加上,否则,生成的 ats 放到 vue 源码中会抛出错误
"props": [],
"children": [{ "type": 2, "content": " hello world " }]
}
],
// loc:位置,这个属性并不影响渲染,但是它必须存在,否则会报错。所以我们给了他一个 {}
"loc": {}
}模板解析的 token 流程为(以 <div>hello world</div> 为例):
1. <div
2. >
3. hello world
4. </div
5. >明确好以上内容之后,我们开始。
进入
baseParse方法执行
createParserContext,生成context上下文对象- 进入
createParserContext方法 - 该方法中返回了一个
ParserContext类型的对象:ParserContext是一个解析器上下文对象,里面包含了非常多的解析器属性- 具体可查看
packages/compiler-core/src/parse.ts中 第92行
- 该对象比较复杂,我们只需要关注
source(模板源代码)这一个属性即可
- 进入
此时
context.source = "<div> hello world </div>"执行
getCursor(context)方法,该方法主要获取loc (即:location 位置),与我们的极简AST无关,无需关注执行
parseChildren方法(解析子节点),这个方法 非常重要,是生成AST的核心方法:进入
parseChildren方法执行
const nodes: TemplateChildNode[] = [],创建nodes变量,这个nodes就是生成的AST中的children执行
while循环,循环解析模板数据:循环的判断条件为
!isEnd(context, mode, ancestors),我们进入到isEnd方法进行查看- 执行
const s = context.source,获取s,此时s = <div> hello world </div> - 不符合
isEnd的条件,返回false,进入循环
- 执行
执行
const s = context.source,此时的s = <div> hello world </div>执行
let node,声明node,这个node就是children中的元素执行
if (mode === TextModes.DATA || mode === TextModes.RCDATA) {...}和else if (mode === TextModes.DATA && s[0] === '<'),因为当前的s = <div> hello world </div>,所以 满足条件。表示为:标签开始执行
else if (/[a-z]/i.test(s[1])),满足条件。表示为:以<开始,后面跟a-z表示,这是一个标签的开始执行
node = parseElement(context, ancestors)方法。即:parseElement的返回值为node,我们知道node为children下的元素,所以说:parseElement即为解析element,生成children下元素的方法进入
parseElement方法,开始解析element,此时context.source = <div> hello world </div>整个
parseElement的解析分为三步:- 开始标签:例如
<div> - 子节点:例如
hello world - 结束标签:例如
</div>
- 开始标签:例如
首先执行 开始标签
<div>的解析:执行
const element = parseTag(context, TagType.Start, parent)方法,parseTag表示为 解析标签- 整个
parseTag方法解析标签共分为两步:- 标签开始:例如:
<div - 标签结束:例如:
>
- 标签开始:例如:
- 整个
进入
parseTag方法,该方法为 解析标签 的方法,主要做了 四件 事情:首先处理 标签开始
- 代码执行:
const match = /^<\/?([a-z][^\t\r\n\f />]*)/i.exec(context.source)! - 代码执行:
const tag = match[1]。利用match这个正则,拿到tag标签名,此时标签名为tag = div - 执行
advanceBy(context, match[0].length)方法,此处的 advanceBy 方法 非常重要。- 该方法的的作用,主要为:解析模板
- 针对于
<div>hello world</div>而言,一共会被解析5次,解析的顺序为: - 第一次解析:
<div:此时context.source = >hello world</div> - 第二次解析:
>:此时context.source = hello world</div> - 第三次解析:
hello world:此时context.source = </div> - 第四次解析:
</div:此时context.source = > - 第五次解析:
>:此时context.source = '' - 此时为 第一次解析:
<div:此时context.source = >hello world</div>
- 代码执行:
接下来处理 标签结束
- 执行
let isSelfClosing,创建isSelfClosing变量,该变量表示为关闭标签。 - 执行
isSelfClosing = startsWith(context.source, '/>')。即:context.source此时以/>即为,则isSelfClosing = true。否则为false - 再次执行
advanceBy(context, isSelfClosing ? 2 : 1),此时为: 第一次解析:>:此时context.source = hello world</div>
- 执行
标记 标签类型:
- 执行
let tagType = ElementTypes.ELEMENT。标记当前的tagType为element类型。
- 执行
返回
element对象此时返回的对象为
element对象,值为: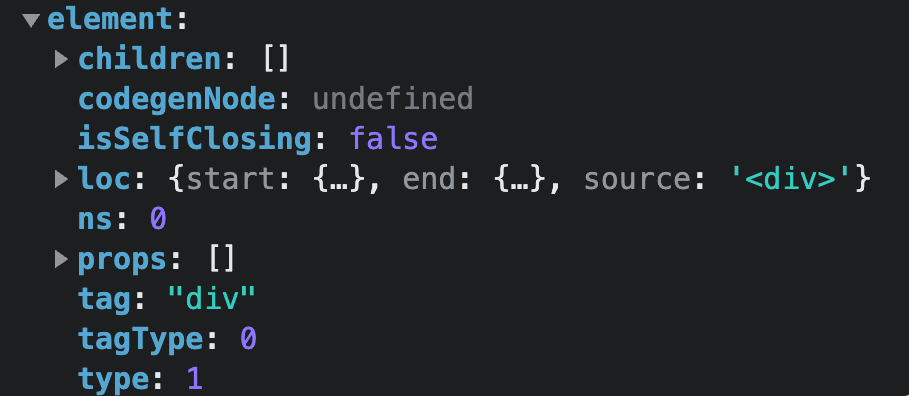
此时
context.source已经被处理了:<div和>两个token,剩余的context.source为: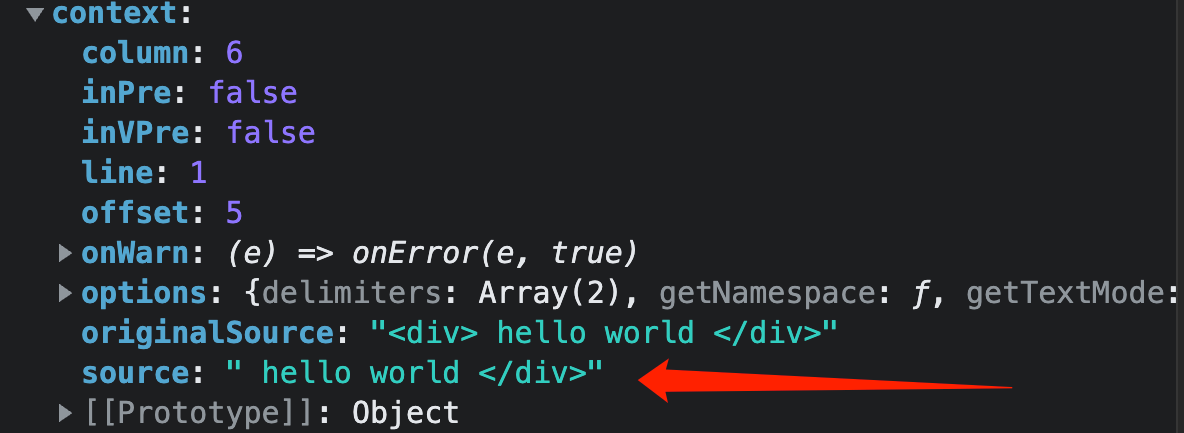
此时
parseTag执行完成,标记着 开始标签:例如<div>处理完成接下来处理 子节点
children:代码执行
ancestors.push(element)- 其中
ancestors表示父节点的意思 - 即:把刚才得到的
element对象放入到ancestors中
- 其中
执行
parseChildren方法,处理子节点。注意:parseChildren此时 第二次 被调用,用于处理 子节点hello world再次进入
parseChildren方法执行同样的逻辑,但是,因为此时的
s: " hello world </div>"。所以会执行node = parseText(context, mode),表示:处理文本节点(hello world)进入
parseText方法执行
const endTokens = xxx。此时endTokens的值为['<', '{{']endTokens表示:普通文本的结束token。例如:hello world </div>,那么文本结束的标记就为 <PS:这也意味着如果你渲染了一个<div> hell<o </div>的标签,那么你将得到一个 错误
执行
let endIndex = context.source.length。其中endIndex表示 普通文本结束的位置执行
for循环,计算endIndex的值。计算的逻辑为:从context.source中分别获取'<', '{{'的下标,取最小值为endIndex代码执行完成之后:
endIndex = 13。执行
const content = parseTextData(context, endIndex, mode),获取 文本内容。该方法主要做了三件事:- 获取文本内容:
- 执行
context.source.slice(0, length)方法 - 触发 第三次解析:
- 触发
advanceBy方法进行 第三次解析,此时解析的内容为:hello world:此时context.source = </div> - 返回文本:
- 执行
return rawText
至此
parseText方法执行完成,它将返回一个 children,值为: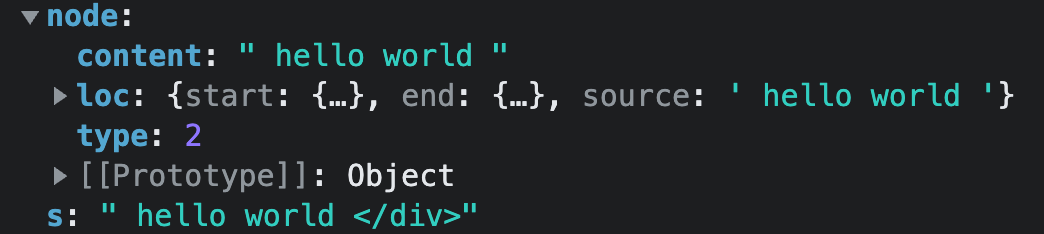
此时
context.source = </div>
执行
pushNode(nodes, node),把node作为nodes的子节点,此时nodes的值为:
返回
parseElement方法中,得到的children即为nodes最后在
ancestors中pop出子节点
此时,子节点
hello world处理完成执行
element.children = children,即: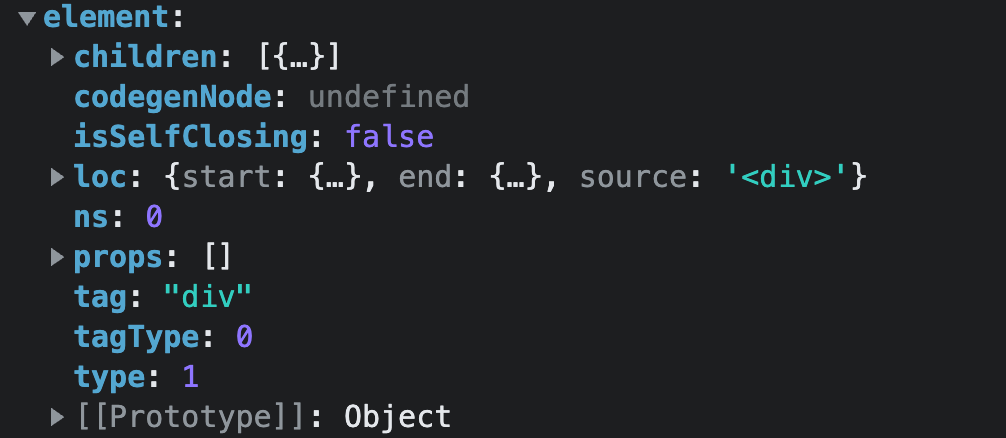
最后处理 结束标签
</div>:- 执行
f (startsWithEndTagOpen(context.source, element.tag))方法- 该方法比较简单,其作用是:判断当前是否为《标签结束的开始》。比如
</div>就是div标签结束的开始
- 该方法比较简单,其作用是:判断当前是否为《标签结束的开始》。比如
- 再次执行
parseTag方法处理结束标签:- 再次进入
parseTag方法,此次进入我们将处理结束标签</div>- 标签开始
- 执行
const tag = match[1],拿到的tag = div - 执行
advanceBy方法,此时为 第四次解析:</div:此时context.source = >
- 执行
- 标签结束
- 执行
isSelfClosing = startsWith(context.source, '/>'),结果isSelfClosing = false - 执行
advanceBy方法,此时为 第五次解析:>:此时context.source = ''
- 执行
- 标签开始
- 再次进入
- 执行
至此:整个
template已经全部解析完成这也标记着
parseElement方法执行完成,得到的element为: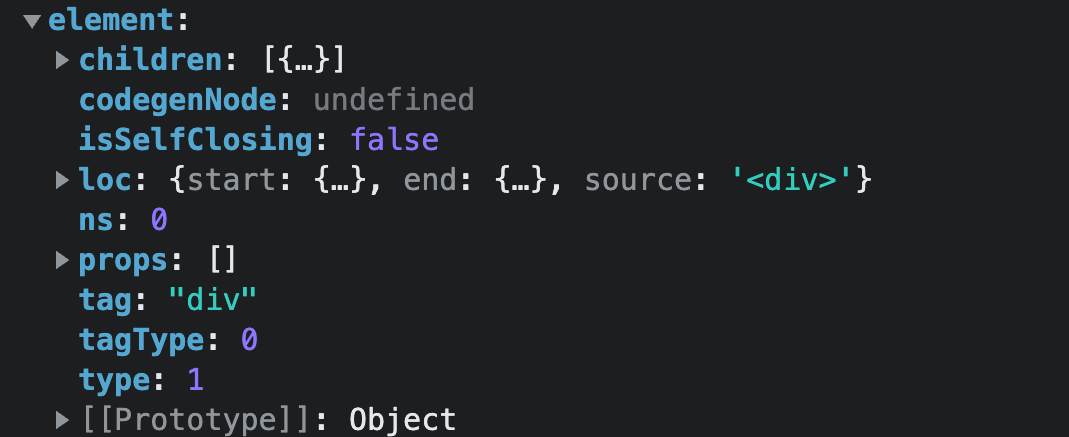
该
element将被作为返回值返回
至此:
node = parseElement(context, ancestors)执行完成,此时的node为上图element执行
pushNode(nodes, node),赋值给nodes此时的
nodes为:
至此,整个
parseChildren执行完成,得到nodes,并返回
parseChildren方法执行完成:children = nodes(上图)最后执行
createRoot方法:- 进入
createRoot方法,该方法就比较简单了。 - 只是返回了一个:以
NodeTypes.ROOT为根节点,nodes为children的AST对象
- 进入
至此我们 成功 得到了
AST对象
由以上代码可知:
- 整个
AST生成的核心就是parseChildren方法。 - 生成的过程中,对整个
template:<div> hello world </div>进行了解析,整个解析分为5步(第二小节的讲解):- 第一次解析:
<div:此时context.source = >hello world</div> - 第二次解析:
>:此时context.source = hello world</div> - 第三次解析:
hello world:此时context.source = </div> - 第四次解析:
</div:此时context.source = > - 第五次解析:
>:此时context.source = ''
- 第一次解析:
- 在这个解析过程中,我们逐步扫描(第三小节的讲解)对应的每次
token,得到了一个对应的AST对象
vue 源码中的 parse 逻辑是非常复杂的,我们当前只是针对 <div>hello world</div> 这一种类型的 element 类型进行了处理。
其他的比如 <pre>、<img /> 这些标签类型的处理,大家可以根据本小节的内容,自己进行测试,我们在课程中就不会一一进行讲解了。
05:框架实现:构建 parse 方法,生成 context 实例
从这一小节开始,我们将实现 vue-next-mini 中的编辑器模块。首先我们第一步要做的就是生成 AST 对象。但是我们知道 AST 对象的生成颇为复杂,所以我们把整个过程分为成三步进行处理。
- 构建
parse方法,生成context实例 - 构建
parseChildren,处理所有子节点(最复杂)- 构建有限自动状态机解析模板
- 扫描 token 生成 AST 结构
- 生成
AST,构建测试
那么本小节,我们就先处理第一步。
创建
packages/compiler-core/src/compile.ts模块,写入如下代码:jsexport function baseCompile(template: string, options) { return {} }创建
packages/compiler-dom/src/index.ts模块,导出compile方法:jsimport { baseCompile } from 'packages/compiler-core/src/compile' export function compile(template: string, options) { return baseCompile(template, options) }在
packages/vue/src/index.ts中,导出compile方法:jsexport { compile } from '@vue/compiler-dom'创建
packages/compiler-core/src/parse.ts模块下创建baseParse方法:js/** * 基础的 parse 方法,生成 AST * @param content tempalte 模板 * @returns */ export function baseParse(content: string) { return {} }在
packages/compiler-core/src/compile.ts模块下的baseCompile中,使用baseParse方法:jsimport { baseParse } from './parse' export function baseCompile(template: string, options) { const ast = baseParse(template) console.log(JSON.stringify(ast)) return {} }
那么至此,我们就成功的触发了 baseParse。接下来我们去生成 context 上下文对象。
在
packages/compiler-core/src/parse.ts中创建createParserContext方法,用来生成上下文对象:js/** * 创建解析器上下文 */ function createParserContext(content: string): ParserContext { // 合成 context 上下文对象 return { source: content } }创建
ParserContext接口:js/** * 解析器上下文 */ export interface ParserContext { // 模板数据源 source: string }在
baseParse中触发该方法:jsexport function baseParse(content: string) { // 创建 parser 对象,未解析器的上下文对象 const context = createParserContext(content) console.log(context) return {} }
那么至此我们成功得到了 context 上下文对象。
我们可以创建测试实例 packages/vue/examples/compiler/compiler-ast.html:
<script>
const { compile } = Vue
// 创建 template
const template = `<div> hello world </div>`
// 生成 render 函数
const renderFn = compile(template)
</script>可以成功打印 context
06:框架实现:构建有限自动状态机解析模板,扫描 token 生成 AST 结构
接下来我们通过 parseChildren 方法处理所有的子节点,整个处理的过程分为两大块:
- 构建有限自动状态机解析模板
- 扫描 token 生成 AST 结构
接下来我们来进行实现:
创建
parseChildren方法:js/** * 解析子节点 * @param context 上下文 * @param mode 文本模型 * @param ancestors 祖先节点 * @returns */ function parseChildren(context: ParserContext, ancestors) { // 存放所有 node节点数据的数组 const nodes = [] /** * 循环解析所有 node 节点,可以理解为对 token 的处理。 * 例如:<div>hello world</div>,此时的处理顺序为: * 1. <div * 2. > * 3. hello world * 4. </ * 5. div> */ while (!isEnd(context, ancestors)) { /** * 模板源 */ const s = context.source // 定义 node 节点 let node if (startsWith(s, '{{')) { } // < 意味着一个标签的开始 else if (s[0] === '<') { // 以 < 开始,后面跟a-z 表示,这是一个标签的开始 if (/[a-z]/i.test(s[1])) { // 此时要处理 Element node = parseElement(context, ancestors) } } // node 不存在意味着上面的两个 if 都没有进入,那么我们就认为此时的 token 为文本节点 if (!node) { node = parseText(context) } pushNode(nodes, node) } return nodes }以上代码中涉及到了 个方法:
isEnd:判断是否为结束节点startsWith:判断是否以指定文本开头pushNode:为array执行push方法- 复杂:
parseElement:解析element - 复杂:
parseText:解析text
我们先实现前三个简单方法:
创建
startsWith方法:js/** * 是否以指定文本开头 */ function startsWith(source: string, searchString: string): boolean { return source.startsWith(searchString) }创建
isEnd方法:js/** * 判断是否为结束节点 */ function isEnd(context: ParserContext, ancestors): boolean { const s = context.source // 解析是否为结束标签 if (startsWith(s, '</')) { for (let i = ancestors.length - 1; i >= 0; --i) { if (startsWithEndTagOpen(s, ancestors[i].tag)) { return true } } } return !s }isEnd方法中使用了startsWithEndTagOpen方法,所以我们要实现它:js/** * 判断当前是否为《标签结束的开始》。比如 </div> 就是 div 标签结束的开始 * @param source 模板。例如:</div> * @param tag 标签。例如:div * @returns */ function startsWithEndTagOpen(source: string, tag: string): boolean { return ( startsWith(source, '</') && source.slice(2, 2 + tag.length).toLowerCase() === tag.toLowerCase() && /[\t\r\n\f />]/.test(source[2 + tag.length] || '>') ) }创建
pushNode方法:js/** * nodes.push(node) */ function pushNode(nodes, node): void { nodes.push(node) }
至此三个简单的方法都被构建完成。
接下来我们来处理 parseElement,在处理的过程中,我们需要使用到 NodeTypes 和 ElementTypes 这两个 enum 对象,所以我们需要先构建它们(直接复制即可):
创建
packages/compiler-core/src/ast.ts模块:js/** * 节点类型(我们这里复制了所有的节点类型,但是我们实际上只用到了极少的部分) */ export const enum NodeTypes { ROOT, ELEMENT, TEXT, COMMENT, SIMPLE_EXPRESSION, INTERPOLATION, ATTRIBUTE, DIRECTIVE, // containers COMPOUND_EXPRESSION, IF, IF_BRANCH, FOR, TEXT_CALL, // codegen VNODE_CALL, JS_CALL_EXPRESSION, JS_OBJECT_EXPRESSION, JS_PROPERTY, JS_ARRAY_EXPRESSION, JS_FUNCTION_EXPRESSION, JS_CONDITIONAL_EXPRESSION, JS_CACHE_EXPRESSION, // ssr codegen JS_BLOCK_STATEMENT, JS_TEMPLATE_LITERAL, JS_IF_STATEMENT, JS_ASSIGNMENT_EXPRESSION, JS_SEQUENCE_EXPRESSION, JS_RETURN_STATEMENT } /** * Element 标签类型 */ export const enum ElementTypes { /** * element,例如:<div> */ ELEMENT, /** * 组件 */ COMPONENT, /** * 插槽 */ SLOT, /** * template */ TEMPLATE }下面就可以构建
parseElement方法了 ,该方法的作用主要为了解析Element元素:创建
parseElement:js/** * 解析 Element 元素。例如:<div> */ function parseElement(context: ParserContext, ancestors) { // -- 先处理开始标签 -- const element = parseTag(context, TagType.Start) // -- 处理子节点 -- ancestors.push(element) // 递归触发 parseChildren const children = parseChildren(context, ancestors) ancestors.pop() // 为子节点赋值 element.children = children // -- 最后处理结束标签 -- if (startsWithEndTagOpen(context.source, element.tag)) { parseTag(context, TagType.End) } // 整个标签处理完成 return element }构建
TagTypeenum:js/** * 标签类型,包含:开始和结束 */ const enum TagType { Start, End }处理开始标签,构建
parseTag:js/** * 解析标签 */ function parseTag(context: any, type: TagType): any { // -- 处理标签开始部分 -- // 通过正则获取标签名 const match: any = /^<\/?([a-z][^\r\n\t\f />]*)/i.exec(context.source) // 标签名字 const tag = match[1] // 对模板进行解析处理 advanceBy(context, match[0].length) // -- 处理标签结束部分 -- // 判断是否为自关闭标签,例如 <img /> let isSelfClosing = startsWith(context.source, '/>') // 《继续》对模板进行解析处理,是自动标签则处理两个字符 /> ,不是则处理一个字符 > advanceBy(context, isSelfClosing ? 2 : 1) // 标签类型 let tagType = ElementTypes.ELEMENT return { type: NodeTypes.ELEMENT, tag, tagType, // 属性,目前我们没有做任何处理。但是需要添加上,否则,生成的 ats 放到 vue 源码中会抛出错误 props: [] } }解析标签的过程,其实就是一个自动状态机不断读取的过程,我们需要构建
advanceBy方法,来标记进入下一步:js/** * 前进一步。多次调用,每次调用都会处理一部分的模板内容 * 以 <div>hello world</div> 为例 * 1. <div * 2. > * 3. hello world * 4. </div * 5. > */ function advanceBy(context: ParserContext, numberOfCharacters: number): void { // template 模板源 const { source } = context // 去除开始部分的无效数据 context.source = source.slice(numberOfCharacters) }至此
parseElement构建完成。此处的代码虽然不多,但是逻辑非常复杂。在解析的过程中,会再次触发parseChildren,这次触发表示触发 文本解析,所以下面我们要处理parseText方法。创建
parseText方法,解析文本:js/** * 解析文本。 */ function parseText(context: ParserContext) { /** * 定义普通文本结束的标记 * 例如:hello world </div>,那么文本结束的标记就为 < * PS:这也意味着如果你渲染了一个 <div> hell<o </div> 的标签,那么你将得到一个错误 */ const endTokens = ['<', '{{'] // 计算普通文本结束的位置 let endIndex = context.source.length // 计算精准的 endIndex,计算的逻辑为:从 context.source 中分别获取 '<', '{{' 的下标,取最小值为 endIndex for (let i = 0; i < endTokens.length; i++) { const index = context.source.indexOf(endTokens[i], 1) if (index !== -1 && endIndex > index) { endIndex = index } } // 获取处理的文本内容 const content = parseTextData(context, endIndex) return { type: NodeTypes.TEXT, content } }解析文本的过程需要获取到文本内容,此时我们需要构建
parseTextData方法:js/** * 从指定位置(length)获取给定长度的文本数据。 */ function parseTextData(context: ParserContext, length: number): string { // 获取指定的文本数据 const rawText = context.source.slice(0, length) // 《继续》对模板进行解析处理 advanceBy(context, length) // 返回获取到的文本 return rawText }
最后在
baseParse中触发parseChildren方法:js/** * 基础的 parse 方法,生成 AST * @param content tempalte 模板 * @returns */ export function baseParse(content: string) { // 创建 parser 对象,未解析器的上下文对象 const context = createParserContext(content) const children = parseChildren(context, []) console.log(children) return {} }此时运行测试实例,应该可以打印出如下内容:
json[ { "type": 1, "tag": "div", "tagType": 0, "props": [], "children": [{ "type": 2, "content": " hello world " }] } ]
07:框架实现:生成 AST,构建测试
当 parseChildren 处理完成之后,我们可以到 children,那么最后我们就只需要利用 createRoot 方法,把 children 放到 ROOT 节点之下即可。
创建
createRoot方法:js/** * 生成 root 节点 */ export function createRoot(children) { return { type: NodeTypes.ROOT, children, // loc:位置,这个属性并不影响渲染,但是它必须存在,否则会报错。所以我们给了他一个 {} loc: {} } }在
baseParse中使用该方法:js/** * 基础的 parse 方法,生成 AST * @param content tempalte 模板 * @returns */ export function baseParse(content: string) { // 创建 parser 对象,未解析器的上下文对象 const context = createParserContext(content) const children = parseChildren(context, []) return createRoot(children) }
至此整个 parse 解析流程完成。我们可以在 packages/compiler-core/src/compile.ts 中打印得到的 AST
export function baseCompile(template: string, options) {
const ast = baseParse(template)
console.log(JSON.stringify(ast))
return {}
}得到的内容为:
{
"type": 0,
"children": [
{
"type": 1,
"tag": "div",
"tagType": 0,
"props": [],
"children": [{ "type": 2, "content": " hello world " }]
}
],
"loc": {}
}我们可以把得到的该 AST 放入到 vue 的源码中进行解析,以此来验证是否正确。
在 vue 源码的 packages/compiler-core/src/compile.ts 模块下 baseCompile 方法中:
export function baseCompile(
template: string | RootNode,
options: CompilerOptions = {}
): CodegenResult {
...
- const ast = isString(template) ? baseParse(template, options) : template
+ const ast = {
+ type: 0,
+ children: [
+ {
+ type: 1,
+ tag: 'div',
+ tagType: 0,
+ props: [],
+ children: [{ type: 2, content: ' hello world ' }]
+ }
+ ],
+ loc: {}
+ }
...
}运行源码的 compile 方法,浏览器中应该可以渲染 hello world:
<script>
const { compile, h, render } = Vue
// 创建 template
const template = ``
// 生成 render 函数
const renderFn = compile(template)
// 创建组件
const component = {
render: renderFn
}
// 通过 h 函数,生成 vnode
const vnode = h(component)
// 通过 render 函数渲染组件
render(vnode, document.querySelector('#app'))
</script>成功运行,标记着我们的 AST 处理完成。
08:扩展知识:AST 到 JavaScript AST 的转化策略和注意事项
在生成了 AST 之后,我们知道接下来就需要把 AST 转化为 JavaScript AST 了,但是在转化的过程中,有一些对应的策略和注意事项,我们需要在本小节中进行描述。
转化策略
我们知道从 AST 转化为 JavaScript AST 本质上是一个对象结构的变化,变化的本质是为了后面更方便的解析对象,生成 render 函数。
在转化的过程中,我们需要遵循如下策略:
- 深度优先
- 转化函数分离
- 上下文对象
深度优先
我们知道 AST 而言,它是包含层级的,比如:
- 最外层是
ROOT children是根节点- …
这样的结构下,就会存在一个自上而下的层级,那么针对这样的一个层级而言,我们需要遵循 深度优先,自下而上 的一个转化方案。
因为父节点的状态往往需要根据子节点的情况才能够进行确定,比如:
<div>hello world</div>
<div>hello {{ msg }}</div>转化函数分离
在处理 AST 的时候,我们知道,针对于不同的 token,那么会使用不同的 parseXXX 方法进行处理,那么同样的,在 transform 的过程中,我们也会通过不同的 transformXXX 方法进行转化。
但是为了防止 transform 模块过于臃肿,所以我们会通过 options的方式对 transformXXX 方法进行注入(类似于 render 的 option)。
所有注入的方法,会生成一个 nodeTransforms 数组,通过 options 传入。
上下文对象
上下文对象即 context,对于上下文对象而言我们其实并不陌生。比如在 parse 时、 setup 函数中、 vuex 的 action 上,都出现过 context 对象。
对于 context 而言,我们可以把它理解为一个 全局变量 或者 单例的全局变量,它是一个多模块都可以访问的唯一对象。
在 transform 的策略中,因为存在 转化函数分离 这样的一个特性,所以我们我们必须要构建出这样的一个 context 对象,用来保存 当前的 node 节点 等数据
注意事项
说完了转化策略之后,我们来看下注意事项。
对于 transform 转化方法而言,vue 本身的实现非常复杂,比如:指令、 … 都会在这里处理。
但是对于我们当前而言,我们不考虑这些复杂的情况,仅查看最简单的静态数据渲染,以此来简化整体逻辑。
09:源码阅读:编译器第二步:转化 AST,得到 JavaScript AST 对象
这一小节,我们就来看下对应的 transform 逻辑,我们创建如下测试实例:
<script>
const { compile } = Vue
// 创建 template
const template = `<div> hello world </div>`
// 生成 render 函数
const renderFn = compile(template)
</script>进入 baseCompile 方法,触发 debugger:
进入
baseCompile方法:执行
transform,注意: 此时tansform方法传递了两个参数:ast:这是我们在parse时生成的AST对象options:这是一个配置对象,里面包含了上一小节说的nodeTransforms
触发
transform方法,该方法即为转化JavaScript AST的核心方法:进入
transform方法执行
createTransformContext,该方法主要为生成context上下文对象进入
createTransformContext方法该方法内部的代码很多,但是整体逻辑比较简单,核心就是创建了一个对象
context,然后执行了return在生成的对象中,我们只需要关注如下几个核心属性即可:
js{ /** * AST 根节点 */ root /** * 每次转化时记录的父节点 */ parent: ParentNode | null /** * 每次转化时记录的子节点索引 */ childIndex: number /** * 当前处理的节点 */ currentNode /** * 协助创建 JavaScript AST 属性 helpers,该属性是一个数组,值为 Symbol(方法名),表示 render 函数中创建 节点 的方法 */ helpers: Map<symbol, number> helper<T extends symbol>(name: T): T /** * 转化方法集合 */ nodeTransforms: any[] }
得到
context上下文对象之后,执行
traverseNode方法,该方法为转化的 核心方法:进入
traverseNode,此时参数为:node:ast对象context:上下文对象
执行
context.currentNode = node,标记当前处理的节点。此时currentNode为最外层的root节点执行
const { nodeTransforms } = context,获取nodeTransforms数组,该数组中封装了所有的节点转化方法执行
const exitFns = []和for循环,该循环的主要作用是:往exitFns数组中依次放入nodeTransform转化方法:- 进入该循环
- 执行
const onExit = nodeTransforms[i](node, context),获取转化方法- 进入
nodeTransforms[i](node, context)中进行查看 - 可以发现虽然执行了很多不同的
transformXXX方法,但是这些方法都有一个共同点就是:return了一个方法。即:transformXXX方法是一个闭包函数,对外返回了一个待执行的方法 - 返回的方法现在未执行,将来会在
exitFns[i]()的时候被触发。 - 所以现在我们不着急查看
- 进入
循环执行完成。
exitFns中将放入所有的transformXXX方法,此时对应的node为root,即:最顶层对象。当前exitFns中的值为:js[ // 转化 element postTransformElement(), // 转化 text transformText() ]执行
switch (node.type),进入switch:- 执行
traverseChildren(node, context),该方法会循环处理所有的子节点- 进入
traverseChildren方法 - 可以看到方法本身的逻辑比较简单,会遍历所有的子节点,以触发
traverseNode - 我们尝试再次进入
traverseNode来进行查看 - 再次进入
traverseNode,此时参数为:node:root下children的第一个节点,即:**type = ELEMENT的div**context:上下文对象
- 再次执行
for循环逻辑,填充exitFns。与上次不同的是此时对应的node为type = ELEMENT的div,即:children[1]。 - 再次触发
switch,执行traverseChildren(node, context)方法,循环处理子节点
- 进入
- 执行
依次迭代,当所有的迭代执行完成之后,代码继续往下执行
代码通过
switch,继续往下执行时,将是从最底层(text节点)开始处理的此时将执行 依次退出 逻辑,在依次退出时,会依次触发
exitFns中保存的方法:jslet i = exitFns.length while (i--) { exitFns[i]() }这里大家需要注意:这是一个
i--的逻辑,这样的逻辑意味着 保存的方法将从后往前执行之前的时候我们说过,
exitFns[i]()中保存着所有的transformXXX方法,每次exitFns[i]()执行都意味着一个transformXXX触发,即:一个节点被转化
那么至此,我们的 traverseNode 方法的讲解就算是完成了,下面我们就需要进入 transformXXX 函数的处理,我们这里主要使用到了两个 transformXXX 方法,分别为:
packages/compiler-core/src/transforms/transformElement.ts中的transformElement方法packages/compiler-core/src/transforms/transformText.ts中的transformText方法
那么下面我们依次来看这两个方法,这两个方法会被多次触发,所以我们可以直接在 exitFns[i]() 中增加断点 :
执行
context.currentNode = node,明确当前的执行节点第一次触发
第一次触发
transformElement方法,其实我们这里触发的验证来说应该是return的postTransformElement函数node = context.currentNode!,利用我们的context的上下文对象,获取到当前的node节点,此时的node节点是:
该节点为 最底层 的节点,满足我们之前所说的深度优先
代码触发
if,不符合条件,直接renturn
第二次触发
第二次触发
transformText方法执行
const children = node.children,此时的children为: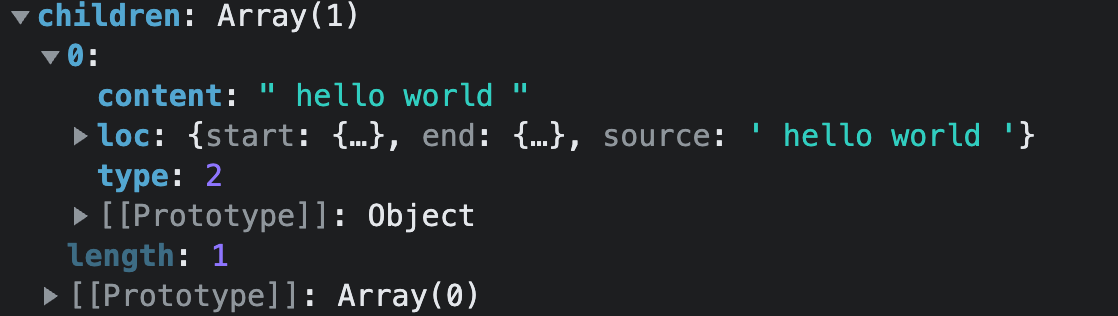
针对于
transformText方法而言,代码非常多,但是并不复杂,当前我们的代码没有办法满足它的运行场景,所以我们直接描述一下它的逻辑:js/** * 方法的作用:将相邻的文本节点和表达式合并为一个表达式。 * * 例如: * <div>hello {{ msg }}</div> * 上述模板包含两个节点: * 1. hello:TEXT 文本节点 * 2. {{ msg }}:INTERPOLATION 表达式节点 * 这两个节点在生成 render 函数时,需要被合并: 'hello' + _toDisplayString(_ctx.msg) * 那么在合并时就要多出来这个 + 加号。 * 例如: * children:[ * { TEXT 文本节点 }, * " + ", * { INTERPOLATION 表达式节点 } * ] */因为我们当前没有
,所以我们无法观察后续执行,后续代码直接跳过
第三次触发
第三次触发
transformElement方法,此时的node节点为: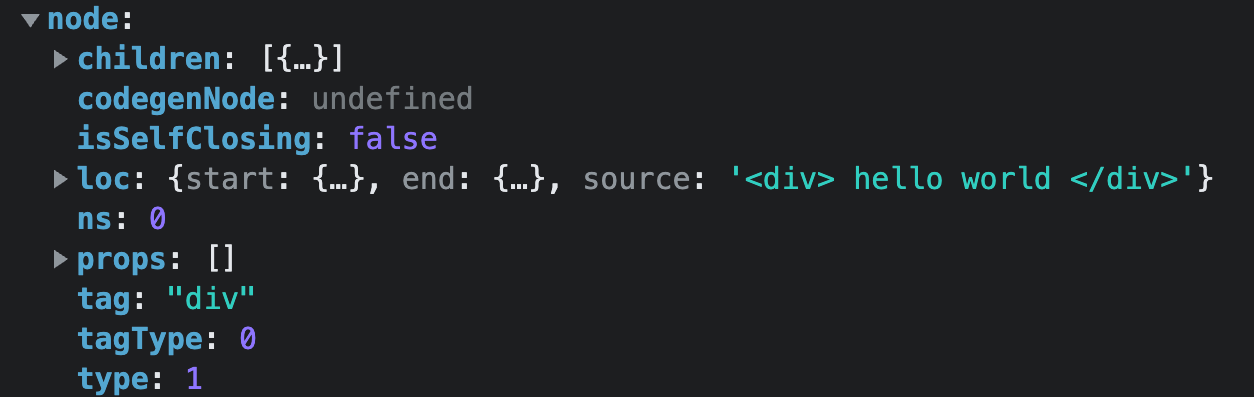
满足条件,触发逻辑
对于该方法而言,内部的代码非常多,但是处理我们无需关注,比如:
props、children…我们直接关注
node.codegenNode = createVNodeCall(...)的逻辑- 进入
createVNodeCall方法 - 执行
context.helper(getVNodeHelper(context.inSSR, isComponent)):- 在这里就利用到了我们生成
context的时候,创建的helper方法和getVNodeHelper方法,我们分别进入这两个方法来看一下- 进入
getVNodeHelper方法- 内部的逻辑非常简单,只是一个三元表达式,直接返回了一个
CREATE_ELEMENT_VNODE的常量,对应的值为Symbol(createElementVNode) - 该常量在生成
render函数时代表了createElementVNode方法:
- 内部的逻辑非常简单,只是一个三元表达式,直接返回了一个
- 进入
helper方法- 该方法也非常简单,只是把刚才的
CREATE_ELEMENT_VNODE这个常量放入到了helpers对象中。 - 针对于
helpers对象:key:函数名value:索引
- 该方法也非常简单,只是把刚才的
- 进入
- 在这里就利用到了我们生成
- 最后
return一个对象
- 进入
该对象即为
codegenNode对象
那么至此,我们看到了两个主要的 transformXXX 方法的执行,后面还会存在多次的执行,我们就不在一个一个去看了。
当所有的 transformXXX 执行完成之后,意味着整个 traverseNode 全部执行完成。traverseNode 执行完成标记着此时:
root的children中将包含有codegenNode对象- 所有的 文本节点和表达式 也都完成了合并
此时所有的 children 都有了 codegenNode 对象,但是对于最外层的 root 还不存在 codegenNode,所有接下来我们要处理最外层的 codegenNode
那么此时我们可以再回到 transform 方法中,继续往下执行:
重新回到
transform方法执行
createRootCodegen(root, context)方法:- 进入
createRootCodegen - 执行
const { children } = root拿到children - 我们当前 只有一个根节点,所以
children.length = 0 - 执行
if (isSingleElementRoot(root, child) && child.codegenNode),确认当前只存在一个根节点 - 拿到第一个子节点的
codegenNode,使其为root的codegenNode
- 进入
至此
root的codegenNode存在值,值为 第一个子节点的codegenNode最后执行:
jsroot.helpers = [...context.helpers.keys()] root.components = [...context.components] root.directives = [...context.directives] root.imports = context.imports root.hoists = context.hoists root.temps = context.temps root.cached = context.cached完成各中值的初始化即可
由以上代码可知:
- 整个
transform的逻辑可以大致分为两部分:- 深度优先排序,通过
traverseNode方法,完成排序逻辑 - 通过保存在
nodeTransforms中的transformXXX方法,针对不同的节点,完成不同的处理
- 深度优先排序,通过
- 期间创建的
context上下文,承担了一个全局单例的作用
10:框架实现:转化 JavaScript AST,构建深度优先的 AST 转化逻辑
明确好了 transform 的大致逻辑之后,这一小节我们就开始实现一下对应的代码,我们代码的逻辑实现我们分成两个小节来讲:
- 深度优先排序
- 完成具体的节点转化
这一小节,我们先来完成深度优先排序:
在
packages/compiler-core/src/compile.ts的baseCompile中,增加transform的方法触发:jsexport function baseCompile(template: string, options = {}) { const ast = baseParse(template) transform( ast, extend(options, { nodeTransforms: [transformElement, transformText] }) ) console.log(JSON.stringify(ast)) return {} }创建
packages/compiler-core/src/transforms/transformElement.ts模块,导出transformElement方法:js/** * 对 element 节点的转化方法 */ export const transformElement = (node, context) => { return function postTransformElement() { } }创建
packages/compiler-core/src/transforms/transformText.ts模块,导出transformText方法:jsexport const transformText = (node, context) => { if ( node.type === NodeTypes.ROOT || node.type === NodeTypes.ELEMENT || node.type === NodeTypes.FOR || node.type === NodeTypes.IF_BRANCH ) { return () => { } } }创建
packages/compiler-core/src/transform.ts模块,创建transform方法:js/** * 根据 AST 生成 JavaScript AST * @param root AST * @param options 配置对象 */ export function transform(root, options) { // 创建 transform 上下文 const context = createTransformContext(root, options) // 按照深度优先依次处理 node 节点转化 traverseNode(root, context) }创建
createTransformContext生成上下文对象:js/** * transform 上下文对象 */ export interface TransformContext { /** * AST 根节点 */ root /** * 每次转化时记录的父节点 */ parent: ParentNode | null /** * 每次转化时记录的子节点索引 */ childIndex: number /** * 当前处理的节点 */ currentNode /** * 协助创建 JavaScript AST 属性 helpers,该属性是一个 Map,key 值为 Symbol(方法名),表示 render 函数中创建 节点 的方法 */ helpers: Map<symbol, number> helper<T extends symbol>(name: T): T /** * 转化方法集合 */ nodeTransforms: any[] } /** * 创建 transform 上下文 */ export function createTransformContext( root, { nodeTransforms = [] } ): TransformContext { const context: TransformContext = { // options nodeTransforms, // state root, helpers: new Map(), currentNode: root, parent: null, childIndex: 0, // methods helper(name) { const count = context.helpers.get(name) || 0 context.helpers.set(name, count + 1) return name } } return context }创建
traverseNode方法:js/** * 遍历转化节点,转化的过程一定要是深度优先的(即:孙 -> 子 -> 父),因为当前节点的状态往往需要根据子节点的情况来确定。 * 转化的过程分为两个阶段: * 1. 进入阶段:存储所有节点的转化函数到 exitFns 中 * 2. 退出阶段:执行 exitFns 中缓存的转化函数,且一定是倒叙的。因为只有这样才能保证整个处理过程是深度优先的 */ export function traverseNode(node, context: TransformContext) { // 通过上下文记录当前正在处理的 node 节点 context.currentNode = node // 获取当前所有 node 节点的 transform 方法 const { nodeTransforms } = context // 存储转化函数的数组 const exitFns: any = [] // 循环获取节点的 transform 方法,缓存到 exitFns 中 for (let i = 0; i < nodeTransforms.length; i++) { const onExit = nodeTransforms[i](node, context) if (onExit) { exitFns.push(onExit) } } // 继续转化子节点 switch (node.type) { case NodeTypes.ELEMENT: case NodeTypes.ROOT: traverseChildren(node, context) break } // 在退出时执行 transform context.currentNode = node let i = exitFns.length while (i--) { exitFns[i]() } } /** * 循环处理子节点 */ export function traverseChildren(parent, context: TransformContext) { parent.children.forEach((node, index) => { context.parent = parent context.childIndex = index traverseNode(node, context) }) }
那么至此,一个按照深度优先依次处理 node 节点转化的逻辑就已经完成
11:框架实现:构建 transformXXX 方法,转化对应节点
在上一小节,我们会依次触发 exitFns[i]() 方法,我们知道这些方法其实是 transformXXX 方法,那么我们依次进行实现:
首先是 transformElement 方法:
在
packages/compiler-core/src/transforms/transformElement.ts模块中实现transformElement方法:js/** * 对 element 节点的转化方法 */ export const transformElement = (node, context) => { return function postTransformElement() { node = context.currentNode! // 仅处理 ELEMENT 类型 if (node.type !== NodeTypes.ELEMENT) { return } const { tag } = node let vnodeTag = `"${tag}"` let vnodeProps = [] let vnodeChildren = node.children node.codegenNode = createVNodeCall( context, vnodeTag, vnodeProps, vnodeChildren ) } }在
packages/compiler-core/src/ast.ts中,创建createVNodeCall方法:jsexport function createVNodeCall(context, tag, props?, children?) { if (context) { context.helper(CREATE_ELEMENT_VNODE) } return { type: NodeTypes.VNODE_CALL, tag, props, children } }创建
packages/compiler-core/src/runtimeHelpers.ts模块:jsexport const CREATE_ELEMENT_VNODE = Symbol('createElementVNode') export const CREATE_VNODE = Symbol('createVNode') /** * const {xxx} = Vue * 即:从 Vue 中可以被导出的方法,我们这里统一使用 createVNode */ export const helperNameMap = { // 在 renderer 中,通过 export { createVNode as createElementVNode } [CREATE_ELEMENT_VNODE]: 'createElementVNode', [CREATE_VNODE]: 'createVNode' }
其次是 transformText 方法:
在
packages/compiler-core/src/transforms/transformText.ts中,完成transformText方法:js/** * 将相邻的文本节点和表达式合并为一个表达式。 * * 例如: * <div>hello {{ msg }}</div> * 上述模板包含两个节点: * 1. hello:TEXT 文本节点 * 2. {{ msg }}:INTERPOLATION 表达式节点 * 这两个节点在生成 render 函数时,需要被合并: 'hello' + _toDisplayString(_ctx.msg) * 那么在合并时就要多出来这个 + 加号。 * 例如: * children:[ * { TEXT 文本节点 }, * " + ", * { INTERPOLATION 表达式节点 } * ] */ export const transformText = (node, context) => { if ( node.type === NodeTypes.ROOT || node.type === NodeTypes.ELEMENT || node.type === NodeTypes.FOR || node.type === NodeTypes.IF_BRANCH ) { return () => { // 获取所有的子节点 const children = node.children // 当前容器 let currentContainer // 循环处理所有的子节点 for (let i = 0; i < children.length; i++) { const child = children[i] if (isText(child)) { // j = i + 1 表示下一个节点 for (let j = i + 1; j < children.length; j++) { const next = children[j] // 当前节点 child 和 下一个节点 next 都是 Text 节点 if (isText(next)) { if (!currentContainer) { // 生成一个复合表达式节点 currentContainer = children[i] = createCompoundExpression( [child], child.loc ) } // 在 当前节点 child 和 下一个节点 next 中间,插入 "+" 号 currentContainer.children.push(` + `, next) // 把下一个删除 children.splice(j, 1) j-- } // 当前节点 child 是 Text 节点,下一个节点 next 不是 Text 节点,则把 currentContainer 置空即可 else { currentContainer = undefined break } } } } } } }在
packages/compiler-core/src/ast.ts中,创建createCompoundExpression方法:js/** * return hello {{ msg }} 复合表达式 */ export function createCompoundExpression(children, loc) { return { type: NodeTypes.COMPOUND_EXPRESSION, loc, children } }创建
packages/compiler-core/src/utils.ts模块,创建isText方法:jsexport function isText(node) { return node.type === NodeTypes.INTERPOLATION || node.type === NodeTypes.TEXT }
至此,两个 transformXXX 方法,都已经创建完成。
此时创建测试实例:
<script>
const { compile } = Vue
// 创建 template
const template = `<div> hello world </div>`
// 生成 render 函数
const renderFn = compile(template)
</script>应该可以打印出 root 之外的 children 的 codegen
12:框架实现:处理根节点的转化,生成 JavaScript AST
那么最后我们就只剩下根节点的处理了。
在
transform方法中:jsexport function transform(root, options) { .... createRootCodegen(root) root.helpers = [...context.helpers.keys()] root.components = [] root.directives = [] root.imports = [] root.hoists = [] root.temps = [] root.cached = [] }创建
createRootCodegen方法:js/** * 生成 root 节点下的 codegen */ function createRootCodegen(root) { const { children } = root // 仅支持一个根节点的处理 if (children.length === 1) { // 获取单个根节点 const child = children[0] if (isSingleElementRoot(root, child) && child.codegenNode) { const codegenNode = child.codegenNode root.codegenNode = codegenNode } } }创建
packages/compiler-core/src/hoistStatic.ts模块,创建isSingleElementRoot方法:js/** * 单个元素的根节点 */ export function isSingleElementRoot(root, child) { const { children } = root return children.length === 1 && child.type === NodeTypes.ELEMENT }
此时,整个 transform 处理完成。运行测试实例,可以得到如下打印:
{
type: 0,
children: [
{
type: 1,
tag: 'div',
tagType: 0,
props: [],
children: [{ type: 2, content: ' hello world ' }],
codegenNode: {
type: 13,
tag: '"div"',
props: [],
children: [{ type: 2, content: ' hello world ' }]
}
}
],
loc: {},
codegenNode: {
type: 13,
tag: '"div"',
props: [],
children: [{ type: 2, content: ' hello world ' }]
},
helpers: [null],
components: [],
directives: [],
imports: [],
hoists: [],
temps: [],
cached: []
}我们可以把如上打印放入到 vue 源代码中的 packages/compiler-core/src/compile.ts 中 baseCompile 方法中。
注意: 需要把 helpers: [null] 改为 helpers: [CREATE_ELEMENT_VNODE]
此时,在 vue 源码中运行如下测试实例:
<script>
const { compile, h, render } = Vue
// 创建 template
const template = ``
// 生成 render 函数
const renderFn = compile(template)
// 创建组件
const component = {
render: renderFn
}
// 通过 h 函数,生成 vnode
const vnode = h(component)
// 通过 render 函数渲染组件
render(vnode, document.querySelector('#app'))
</script>发现可以正常渲染 <div>hello world</div>
13:扩展知识:render 函数的生成方案
当我们得到了 JavaScript AST 之后,下面我们就可以生成对应的 render 函数了。
那么我们如何根据 JavaScript AST 来生成对应的 render 函数呢?
我们先来看 vue 源码生成的 render:
在
packages/compiler-core/src/compile.ts中的baseCompile方法下,使用此代码(咱们自己生成的JavaScript AST):jsreturn generate( { type: 0, children: [ { type: 1, tag: 'div', tagType: 0, props: [], children: [{ type: 2, content: ' hello world ' }], codegenNode: { type: 13, tag: '"div"', props: [], children: [{ type: 2, content: ' hello world ' }] } } ], loc: {}, codegenNode: { type: 13, tag: '"div"', props: [], children: [{ type: 2, content: ' hello world ' }] }, // 此处需要主动写入 helpers: [CREATE_ELEMENT_VNODE], components: [], directives: [], imports: [], hoists: [], temps: [], cached: [] }, extend({}, options, { prefixIdentifiers }) )代替原有的
generate方法调用。在
packages/compiler-core/src/codegen.ts文件中的generate方法的最后位置,打印context.code:jsconsole.log(context.code)
运行测试实例,可以得到如下打印:
const _Vue = Vue
return function render(_ctx, _cache) {
with (_ctx) {
const { createElementVNode: _createElementVNode } = _Vue
return _createElementVNode("div", [], [" hello world "])
}
}该函数就是通过 generate 方法转化得到的 render 函数,在该 render 中存在一个 with (_ctx) 这个代码在我们最终期望得到的 render 函数中是不需要的。所以我们最终期望得到的 render 函数为:
const _Vue = Vue
return function render(_ctx, _cache) {
const { createElementVNode: _createElementVNode } = _Vue
return _createElementVNode("div", [], [" hello world "])
}那么下面我们来分析一下上面这个函数的生成,即:生成方案。
函数的生成方案,分为三部分:
- 函数本质上就是一段字符
- 字符串的拼接方式
- 字符串拼接的格式处理
函数本质上就是一段字符
函数本质上就是一段字符,所以我们可以把以上函数比较一个大的 字符串 。
那么想要生成这样的一个大字符串,本质上就是各个小的字符串的拼接。
例如,我们可以期望如下的拼接:
context.code = `
const _Vue = Vue \n\n return function render(_ctx, _cache) { \n\n const { createElementVNode: _createElementVNode } = _Vue \n\n return _createElementVNode("div", [], [" hello world "]) \n\n }
`把以上字符串处理之后,我们就可以得到一样函数格式的字符:
context.code = `
const _Vue = Vue
return function render(_ctx, _cache) {
const { createElementVNode: _createElementVNode } = _Vue
return _createElementVNode("div", [], [" hello world "])
}
`字符拼接的方式
当我们明确好了函数本身就是字符,这样的概念之后,那么接下来就是如何拼接这样的字符。
我们把上面的函数分成 4 个部分:
函数的前置代码:
const _Vue = Vue函数名:
function render函数的参数:
_ctx, _cache函数体:
jsconst { createElementVNode: _createElementVNode } = _Vue return _createElementVNode("div", [], [" hello world "])
我们只需要把以上的内容拼接到一起,那么就可以得到最终的目标结果。
那么为了完成对应的拼接,我们可以提供一个 push 函数:
function push (code) {
context.code += code
}以此来完成对应的拼接
关于字符串的格式
在去处理这样的一个字符串的过程中,我们不光需要处理拼接,还需要处理对应的格式问题,比如:
context.code = `
const _Vue = Vue
(换行)
return function render(_ctx, _cache) {
(缩进)const { createElementVNode: _createElementVNode } = _Vue
return _createElementVNode("div", [], [" hello world "])
}
`对于字符串而言,我们知道换行可以通过 \n 来进行表示,缩进就是 空格的处理。
所以我们需要再提供对应的方法,来进行对应的处理,比如:
context.indentLevel = 0 // 表示缩进
// 换行
function newline(n: number) {
newline(context.indentLevel)
}
// 缩进+换行
function indent(n: number) {
newline(++context.indentLevel)
}
// 取消缩进 + 换行
function deindent(n: number) {
newline(--context.indentLevel)
}
function newline(n: number) {
context.code += '\n' + ` `.repeat(n)
}14:源码阅读:编译器第三步:生成 render 函数
我们知道生成 render 函数的代码,主要是 packages/compiler-core/src/codegen.ts 中的 generate 方法,所以我们可以直接在该方法中打断点,进入 debugger (注意:此时我们使用的是 vuex-next-mini 生成 JavaScript AST):
进入
generate方法:执行
const context = createCodegenContext(ast, options)得到context上下文:进入
createCodegenContext方法,对于context而言,我们现在是比较熟悉的了,知道它就是一个全局变量观察该方法,可以发现
context内部存在很多属性和方法,这些属性和方法很多,但是我们不需要全部关注,只需要关注如下内容即可:jsconst context = { // render 函数代码字符串 code: ``, // 运行时全局的变量名 runtimeGlobalName: 'Vue', // 模板源 source: ast.loc.source, // 缩进级别 indentLevel: 0, // 需要触发的方法,关联 JavaScript AST 中的 helpers helper(key) { return `_${helperNameMap[key]}` }, /** * 插入代码 */ push(code) { context.code += code }, /** * 新的一行 */ newline() { newline(context.indentLevel) }, /** * 控制缩进 + 换行 */ indent() { newline(++context.indentLevel) }, /** * 控制缩进 + 换行 */ deindent() { newline(--context.indentLevel) } }这些代码相对而言,比较简单,我们在上一小节也提到过对应的作用,这里就不在赘述了。
执行完成该方法之后,我们可以得到一个
context.code目前值为 “”接下来的代码执行,就是不断往
context.code填充内容的过程代码执行
genFunctionPreamble(ast, preambleContext):- 进入
genFunctionPreamble方法 - 执行
if (ast.helpers.length > 0)满足条件- 执行
push(const _Vue = ${VueBinding}\n) - 当前的
VueBinding = Vue,所以以上等同于push(const _Vue = Vue\n) - 此时,
context.code = "const _Vue = Vue\n"
- 执行
- 执行
newline(),此时,context.code = "const _Vue = Vue\n\n" - 执行
push(return),此时,context.code = "const _Vue = Vue\n\nreturn"
- 进入
genFunctionPreamble执行完成,此时,context.code = "const _Vue = Vue\n\nreturn"代码继续执行,生成
functionName和args执行
push(function functionName(signature}) {),此时,context.code = "“const _Vue = Vue\n\nreturn function render(_ctx, _cache) {”"执行
indent(),此时,context.code = "const _Vue = Vue\n\nreturn function render(_ctx, _cache) {\n "执行
push(with (_ctx) {)。- 此时,
context.code = "const _Vue = Vue\n\nreturn function render(_ctx, _cache) {\n with (_ctx) {"
- 此时,
执行
indent()。此时,context.code = "const _Vue = Vue\n\nreturn function render(_ctx, _cache) {\n with (_ctx) { \n"执行:
jspush(`const { ${ast.helpers.map(aliasHelper).join(', ')} } = _Vue`) push(`\n`) newline()此时,
jscontext.code = "const _Vue = Vue\n\nreturn function render(_ctx, _cache) {\n with (_ctx) {\n const { createElementBlock: _createElementBlock } = _Vue\n\n "执行
push(return)此时:
jscontext.code = "const _Vue = Vue\n\nreturn function render(_ctx, _cache) {\n with (_ctx) {\n const { createElementBlock: _createElementBlock } = _Vue\n\n return"那么到此为止,对于
code而言,就只剩下最后一块内容,也就是 :js_createElementVNode("div", [], [" hello world "])而这里,也是整个
generate最复杂的一块逻辑这块逻辑由
genNode(ast.codegenNode, context)开始,我们进入到genNode方法进入
genNode方法,目前的参数node为: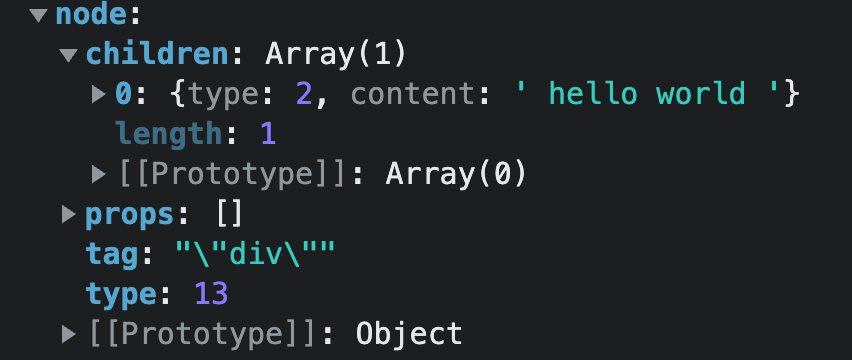
代码执行
switch:当前的
type为13,对应case NodeTypes.VNODE_CALL所以触发
genVNodeCall方法进入
genVNodeCall方法代码执行
const callHelper: symbol = xxx,这里的isBlock = undefined,所以会触发getVNodeHelper(context.inSSR, isComponent)方法:进入
getVNodeHelper方法:该方法的内部执行非常简单:
jsreturn ssr || isComponent ? CREATE_VNODE : CREATE_ELEMENT_VNODE返回了两个
Symbol,分别对应createVNode和createElementVNode方法此处返回
CREATE_ELEMENT_VNODE
执行
push(helper(callHelper) +(, node)此时:
jscontext.code = "const _Vue = Vue\n\nreturn function render(_ctx, _cache) {\n with (_ctx) {\n const { createElementBlock: _createElementBlock } = _Vue\n\n return _createElementVNode("接下来我们就需要为 方法填充参数:
执行
const args = genNullableArgs(...)进入
genNullableArgs方法,此时的arg参数为:
执行
for循环,最终返回值为: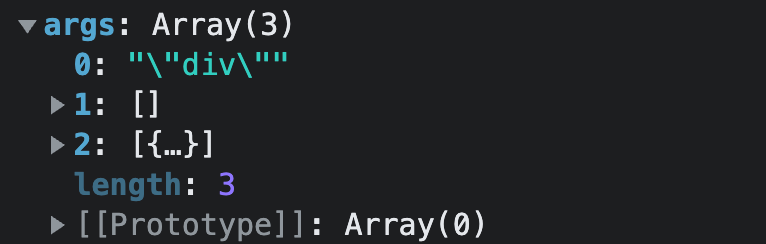
代码执行
genNodeList(args, context), 处理参数的push执行
for循环,循环会被触发3次:第一次触发:
node = 'div'- 直接执行
push(node) - 执行
push(', ')
- 直接执行
第二次触发:
node =[]- 执行
genNodeListAsArray(node, context)- 执行
context.push([) - 执行
context.push(])
- 执行
- 跳出方法,执行
push(', ')
- 执行
第三次触发:

执行
genNodeListAsArray(node, context)执行
context.push([)执行
genNodeList(nodes, context, multilines)通常触发
for循环,此时:node的值为: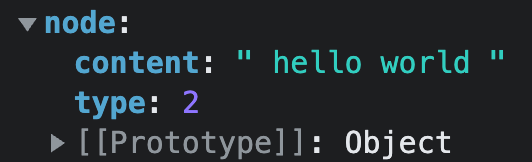
执行
genNode(node, context)- 进入
genNode - 执行
genText(node, context) - 进入
genText - 执行
context.push(JSON.stringify(node.content), node)插入 - 执行
context.push(]) - 跳出方法,执行
push(', ')
- 进入
整个
genNodeList方法执行完成此时:
jscontext.code = "const _Vue = Vue return function render(_ctx, _cache) { with (_ctx) { const { createElementVNode: _createElementVNode } = _Vue return _createElementVNode("div", [], [" hello world "]"
最后返回到
generate方法,处理最后的文本即可
那么由以上代码可知:
- 整个的
generate处理就已经完成了,其中最复杂的部分就是 函数参数的拼接,即genNode(ast.codegenNode, context)的处理- 这里的处理会涉及到一个迭代的循环处理,根据
[tag, props, children, patchFlag, dynamicProps]的值来进行循环的参数处理
- 这里的处理会涉及到一个迭代的循环处理,根据
- 而对于其他的内容而言,本质上就只是一个 字符串的拼接,这些拼接将通过
context上下文对象中的方法:pushnewineindentdeindent
- 来进行实现。
15:框架实现:构建 CodegenContext 上下文对象
对于 generate 的构建,我们将分成两部分来进行实现:
- 构建
context上下文对象 - 利用
context完成函数拼接
那么这一小节,我们先实现第一部分
在
packages/compiler-core/src/compile.ts的baseCompile方法中,完成generate的调用:jsexport function baseCompile(template: string, options = {}) { ... return generate(ast) }创建
packages/compiler-core/src/codegen.ts模块,构建generate和createCodegenContext方法:js/** * 根据 JavaScript AST 生成 */ export function generate(ast) { // 生成上下文 context const context = createCodegenContext(ast) // 获取 code 拼接方法 const { push, newline, indent, deindent } = context ... }jsfunction createCodegenContext(ast) { const context = { // render 函数代码字符串 code: ``, // 运行时全局的变量名 runtimeGlobalName: 'Vue', // 模板源 source: ast.loc.source, // 缩进级别 indentLevel: 0, // 需要触发的方法,关联 JavaScript AST 中的 helpers helper(key) { return `_${helperNameMap[key]}` }, /** * 插入代码 */ push(code) { context.code += code }, /** * 新的一行 */ newline() { newline(context.indentLevel) }, /** * 控制缩进 + 换行 */ indent() { newline(++context.indentLevel) }, /** * 控制缩进 + 换行 */ deindent() { newline(--context.indentLevel) } } function newline(n: number) { context.code += '\n' + ` `.repeat(n) } return context }
那么至此,我们就完成了 CodegenContext 上下文对象的构建
16:框架实现:解析 JavaScript AST,拼接 render 函数
我们最终解析之后的目标函数如下:
const _Vue = Vue
return function render(_ctx, _cache) {
const { createElementVNode: _createElementVNode } = _Vue
return _createElementVNode("div", [], [" hello world "])
}依次,首先我们先生成 除参数之外 部分:
在
generate中:js/** * 根据 JavaScript AST 生成 */ export function generate(ast) { // 生成上下文 context const context = createCodegenContext(ast) // 获取 code 拼接方法 const { push, newline, indent, deindent } = context // 生成函数的前置代码:const _Vue = Vue genFunctionPreamble(context) // 创建方法名称 const functionName = `render` // 创建方法参数 const args = ['_ctx', '_cache'] const signature = args.join(', ') // 利用方法名称和参数拼接函数声明 push(`function ${functionName}(${signature}) {`) // 缩进 + 换行 indent() // 明确使用到的方法。如:createVNode const hasHelpers = ast.helpers.length > 0 if (hasHelpers) { push(`const { ${ast.helpers.map(aliasHelper).join(', ')} } = _Vue`) push(`\n`) newline() } // 最后拼接 return 的值 newline() push(`return `) .... }创建
genFunctionPreamble方法:js/** * 生成 "const _Vue = Vue\n\nreturn " */ function genFunctionPreamble(context) { const { push, newline, runtimeGlobalName } = context const VueBinding = runtimeGlobalName push(`const _Vue = ${VueBinding}\n`) newline() push(`return `) }创建
aliasHelper:jsconst aliasHelper = (s: symbol) => `${helperNameMap[s]}: _${helperNameMap[s]}`运行此时的代码,我们应该可以得到这样的函数生成:
jsconst _Vue = Vue return function render(_ctx, _cache) { const { createElementVNode: _createElementVNode } = _Vue return
那么接下来我们就处理最后 renturn 函数的部分:
补全
generate中的代码:js/** * 根据 JavaScript AST 生成 */ export function generate(ast) { ... // 处理 renturn 结果。如:_createElementVNode("div", [], [" hello world "]) if (ast.codegenNode) { genNode(ast.codegenNode, context) } else { push(`null`) } // 收缩缩进 + 换行 deindent() push(`}`) return { ast, code: context.code } }创建
genNode函数js/** * 区分节点进行处理 */ function genNode(node, context) { switch (node.type) { case NodeTypes.VNODE_CALL: genVNodeCall(node, context) break case NodeTypes.TEXT: genText(node, context) break } }创建
genText函数:js/** * 处理 TEXT 节点 */ function genText(node, context) { context.push(JSON.stringify(node.content), node) }创建
genVNodeCall函数:js/** * 处理 VNODE_CALL 节点 */ function genVNodeCall(node, context) { const { push, helper } = context const { tag, props, children, patchFlag, dynamicProps, isComponent } = node // 返回 vnode 生成函数 const callHelper = getVNodeHelper(context.inSSR, isComponent) push(helper(callHelper) + `(`, node) // 获取函数参数 const args = genNullableArgs([tag, props, children, patchFlag, dynamicProps]) // 处理参数的填充 genNodeList(args, context) push(`)`) }创建
packages/compiler-core/src/utils.ts模块,添加getVNodeHelper方法:js/** * 返回 vnode 生成函数 */ export function getVNodeHelper(ssr: boolean, isComponent: boolean) { return ssr || isComponent ? CREATE_VNODE : CREATE_ELEMENT_VNODE }创建
genNullableArgs函数:js/** * 处理 createXXXVnode 函数参数 */ function genNullableArgs(args: any[]) { let i = args.length while (i--) { if (args[i] != null) break } return args.slice(0, i + 1).map((arg) => arg || `null`) }创建
genNodeList函数js/** * 处理参数的填充 */ function genNodeList(nodes, context) { const { push, newline } = context for (let i = 0; i < nodes.length; i++) { const node = nodes[i] // 字符串直接 push 即可 if (isString(node)) { push(node) } // 数组需要 push "[" "]" else if (isArray(node)) { genNodeListAsArray(node, context) } // 对象需要区分 node 节点类型,递归处理 else { genNode(node, context) } if (i < nodes.length - 1) { push(', ') } } }创建
genNodeListAsArray函数:jsfunction genNodeListAsArray(nodes, context) { context.push(`[`) genNodeList(nodes, context) context.push(`]`) }
至此函数生成完成。接下来我们就来测试一下函数是否可用。
创建如下测试实例:
<script>
const { compile, h, render } = Vue
// 创建 template
const template = `<div> hello world </div>`
// 生成 render 函数
const { code } = compile(template)
console.log(code);
const renderFn = new Function(code)()
// 创建组件
const component = {
render: renderFn
}
// 通过 h 函数,生成 vnode
const vnode = h(component)
// 通过 render 函数渲染组件
render(vnode, document.querySelector('#app'))
</script>打印当前的 code 为:
const _Vue = Vue
return function render(_ctx, _cache) {
const { createElementVNode: _createElementVNode } = _Vue
return _createElementVNode("div", [], [" hello world "])
}由以上代码可知,render 函数使用到了 createElementVNode 方法,所以我们需要在 runtime 时,导出该方法:
在
packages/runtime-core/src/vnode.ts中,新增:js// createElementVNode 实际调用的是 createVNode export { createVNode as createElementVNode }在
packages/runtime-core/src/index.ts中,增加createElementVNode的导出:jsexport { ..., createElementVNode } from './vnode'在
packages/vue/src/index.ts中,增加createElementVNode的导出jsexport { ... createElementVNode } from '@vue/runtime-core'
此时,浏览器中,应该可以成功渲染。
17:框架实现:新建 compat 模块,把 render 转化为 function
此时,我们的 render 函数构建,已经可以完成了。但是我们当前的 render 本质上还是一个 字符串 ,所以我们需要通过 new Function 来把它变为函数。
那么这样的一个 new Function 的过程,我们其实可以在 vue 中完成。
创建
packages/vue-compat/src/index.ts模块新增
compileToFunction方法:jsimport { compile } from '@vue/compiler-dom' function compileToFunction(template, options?) { const { code } = compile(template, options) const render = new Function(code)() return render } export { compileToFunction as compile }在
packages/vue/src/index.ts中修改compile的导出:js// export { compile } from '@vue/compiler-dom' export { compile } from '@vue/vue-compat'修改测试实例:
html<script> const { compile, h, render } = Vue // 创建 template const template = `<div> hello world </div>` // 生成 render 函数 const renderFn = compile(template) // 创建组件 const component = { render: renderFn } // 通过 h 函数,生成 vnode const vnode = h(component) // 通过 render 函数渲染组件 render(vnode, document.querySelector('#app')) </script>
至此,compile 处理完成。
18:总结
到这里我们就已经完成了一个基础的编辑器处理。
我们知道整个编辑器的处理过程分成了三部分:
- 解析模板
template为AST- 在这一步过程中,我们使用了
- 有限自动状态机解析模板得到了
tokens - 通过扫描
tokens最终得到了AST
- 有限自动状态机解析模板得到了
- 在这一步过程中,我们使用了
- 转化
AST为JavaScript AST- 这一步是为了最终生成
render函数做准备 - 利用了深度优先的方式,进行了自下向上的逐层转化
- 这一步是为了最终生成
- 生成
render函数- 这一步是最后的解析环节,我们需要对
JavaScript AST进行处理,得到最终的render函数
- 这一步是最后的解析环节,我们需要对
整个一套编辑器的流程非常复杂,我们目前只完成了最基础的编辑逻辑,目前只能支持 <div>文本</div> 的处理。那么如果我们想要处理更复杂的逻辑,比如:
- 响应性数据
- 多个子节点
- 指令
的话,对比编辑器而言,还需要做更多的事情才可以。
下一章,我们会深入编辑器,来看一下,以上问题应该如何进行处理。