第十一章:runtime 运行时 - diff 算法核心实现
01:前言
我们之前完成过一个 patchChildren 的方法,该方法的主要作用是为了 更新子节点,即:为子节点打补丁。
子节点的类型多种多样,如果两个 ELEMENT 的子节点都是 TEXT_CHILDREN 的话,那么直接通过 setText 附新值即可。
但是如果 新旧 ELEMENT 的子节点都为 ARRAY_CHILDREN 的话,那么想要完成一个 高效 的更新就会比较复杂了。这个时候,我们就需要,比较两组子节点,以达到一个高效的更新功能。这种 比较的算法 就是 diff 算法。
vue 中对 diff 算法的描述在 packages/runtime-core/src/renderer.ts 的 patchKeyedChildren(1759行) 方法中,观察该方法,可以发现该方法内部被分成了 5 块( 5 种场景):
sync from start:自前向后的对比sync from end:自后向前的对比common sequence + mount:新节点多于旧节点,需要挂载common sequence + unmount:旧节点多于新节点,需要卸载unknown sequence:乱序
这 5 块就是 diff 的核心逻辑。
那么我们在后面学习的时候,也会从这 5 块入手,循序渐进的和大家一起来了解 diff。
02:前置知识:VNode 虚拟节点 key 属性的作用
再去学习 diff 之前,我们需要先了解一个前置的知识点。
我们知道在 v-for 循环的时候,我们必须要指定一个 key 值。那么这个 key 值的作用是什么呢?
我们之前写过一个方法: packages/runtime-core/src/vnode.ts 中的 isSameVNodeType 方法。
该方法是用来判断两个 VNode 是否为相同 VNode 的方法:
/**
* 根据 key || type 判断是否为相同类型节点
*/
export function isSameVNodeType(n1: VNode, n2: VNode): boolean {
return n1.type === n2.type && n1.key === n2.key
}在这个代码中,type 我们知道什么意思。但是这个 key 是干什么呢的?
这里的 key 是一个 props,比如我们可以在 vue 源码中,利用 h 函数,构建这样的一个 VNode:
const vnode = h('li', {
key: 1,
}, '1')VNode 的值为:
{
"__v_isVNode": true,
"type": "li",
"props": { "key": 1 },
"key": 1,
"children": "1",
"shapeFlag": 9,
....
}此时我们可以发现,VNode 中多出了一个 key 的属性,值为 1。
如果我们通过 isSameVNodeType方法,判断两个 VNode 是否为 相同的 VNode,则只需要保证两个 VNode 的 type 和 key 相同即可:
const vnode = h('li', {
key: 1,
}, '1')
const vnode2 = h('li', {
key: 1,
}, '2')
isSameVNodeType(vnode, vnode2) // true这个概念在 diff 中非常重要,它决定了 ELEMENT 的 复用 逻辑。具体怎么复用,我们会在后面进行详细讲解。
对于现在我们的代码而言,目前还不能增加 key 属性,所以我们需要为我们的代码增加 key 属性的挂载:
- 在
packages/runtime-core/src/vnode.ts的createBaseVNode中,增加key属性:
const vnode = {
__v_isVNode: true,
type,
props,
shapeFlag,
+ key: props?.key || null
} as VNode这样,我们的 vnode 就可以具备 key 属性了。
03:源码阅读:场景一:自前向后的 diff 对比
我们创建如下测试实例 packages/vue/examples/imooc/runtime/render-element-diff.html:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'c'),
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'd')
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>在上面的测试实例中,我们利用 vnode 2 更新 vnode 节点。
它们的子节点都是一个 ARRAY_CHILDREN ,需要注意的是它们的 **子节点具备相同顺序下的相同 vnode (type、key 相等) **。唯一不同的地方在于 第三个 li 标签显示的内容不同
那么我们来看一下这种情况下 vue 是如何来处理对应的 diff 的。
在 patchKeyedChildren 中,进行 debugger,等待两秒,进入 debugger:
进入
patchKeyedChildren方法,此时各参数的值为:
- 其中
c1表示为:旧的子节点,即:oldChildren c2表示为:新的子节点,即:newChildren
- 其中
执行
let i = 0,声明了一个 计数变量i,初始为0执行
const l2 = c2.length。此时的l2表示为 新的子节点的长度,即:newChildrenLength执行
let e1 = c1.length - 1。此时的e1表示为 旧的子节点最大(最后一个)下标,即:oldChildrenEnd执行
let e2 = l2 - 1。此时的e2表示为 **新的子节点最大(最后一个)下标,**即:newChildrenEnd执行
while循环:while (i <= e1 && i <= e2)第一次 进入
while循环:此时
n1的值为:jsh('li', { key: 1 }, 'a') 代码块 预览复制123此时
n2的值为:jsh('li', { key: 1 }, 'a') 代码块123那么根据上一小节所说,我们知道,此时
isSameVNodeType(n1, n2)会被判定为true所以此时执行
patch方法,进行打补丁即可。最后执行:
i++至此,第一次循环完成
第二次 进入
while循环:- 根据刚才所知,此时的
n1和n2依然符合isSameVNodeType(n1, n2)的判定 - 所以,依然会执行
patch方法,进行打补丁。 - 最后执行:
i++ - 至此,第二次循环完成
- 根据刚才所知,此时的
第三次 进入
while循环:- 根据刚才所知,此时的
n1和n2依然符合isSameVNodeType(n1, n2)的判定 - 所以,依然会执行
patch方法,进行打补丁。 - 最后执行:
i++ - 至此,第三次循环完成
- 根据刚才所知,此时的
三次循环全部完成,此时,我们查看浏览器,可以发现
children的 更新 操作 已经完成。后续的代码无需关心。
由以上代码可知:
diff所面临的的第一个场景就是:自前向后的 diff 比对- 在这样的一个比对中,会 依次获取相同下标的
oldChild和newChild:- 如果
oldChild和newChild为 相同的VNode,则直接通过patch进行打补丁即可 - 如果
oldChild和newChild为 不相同的VNode,则会跳出循环
- 如果
- 每次处理成功,则会自增
i标记,表示:自前向后已处理过的节点数量
04:框架实现:场景一:自前向后的 diff 对比
根据我们上一小节所描述的内容,下面我们可以直接实现对应逻辑。
首先我们先让我们的代码支持
ARRAY_CHILDREN的渲染。- 在
packages/runtime-core/src/renderer.ts中mountElement中:
jselse if (shapeFlag & ShapeFlags.ARRAY_CHILDREN) { // 设置 Array 子节点 mountChildren(vnode.children, el, anchor) }- 在
接下来我们来处理
diff在
packages/runtime-core/src/renderer.ts中,创建patchKeyedChildren方法:js/** * diff */ const patchKeyedChildren = (oldChildren, newChildren, container, parentAnchor) => { /** * 索引 */ let i = 0 /** * 新的子节点的长度 */ const newChildrenLength = newChildren.length /** * 旧的子节点最大(最后一个)下标 */ let oldChildrenEnd = oldChildren.length - 1 /** * 新的子节点最大(最后一个)下标 */ let newChildrenEnd = newChildrenLength - 1 // 1. 自前向后的 diff 对比。经过该循环之后,从前开始的相同 vnode 将被处理 while (i <= oldChildrenEnd && i <= newChildrenEnd) { const oldVNode = oldChildren[i] const newVNode = normalizeVNode(newChildren[i]) // 如果 oldVNode 和 newVNode 被认为是同一个 vnode,则直接 patch 即可 if (isSameVNodeType(oldVNode, newVNode)) { patch(oldVNode, newVNode, container, null) } // 如果不被认为是同一个 vnode,则直接跳出循环 else { break } // 下标自增 i++ } }在
patchChildren方法中,触发patchKeyedChildren方法:jsif (shapeFlag & ShapeFlags.ARRAY_CHILDREN) { // 这里要进行 diff 运算 patchKeyedChildren(c1, c2, container, anchor) }
创建对应测试实例 packages/vue/examples/runtime/render-element-diff.html:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'c'),
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'd')
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>05:源码阅读:场景二:自后向前的 diff 对比
上一小节的代码,只可能处理 自前向后完全相同的 vnode。如果 vnode 不是自前向后完全相同的则无法进行处理,比如我们看下面的例子 packages/vue/examples/imooc/runtime/render-element-diff-2.html:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'c'),
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 4
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'd')
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>在上面的例子中, vnode 2 的第一个子节点的 key = 4,这就会导致一个情况:**如果我们从前往后进行 diff 比对,那么第一个 child 无法满足 isSameVNodeType ,就会直接跳出 **
所以以上案例,在 我们现在的 vue-next-mini 中,是无法进行正确更新的。
那么想要以上场景可以正确更新,就需要继续来查看 vue 中对于 diff 的第二个场景处理 自后向前的 diff 对比:
进入
patchKeyedChildren方法,此时各参数的值为: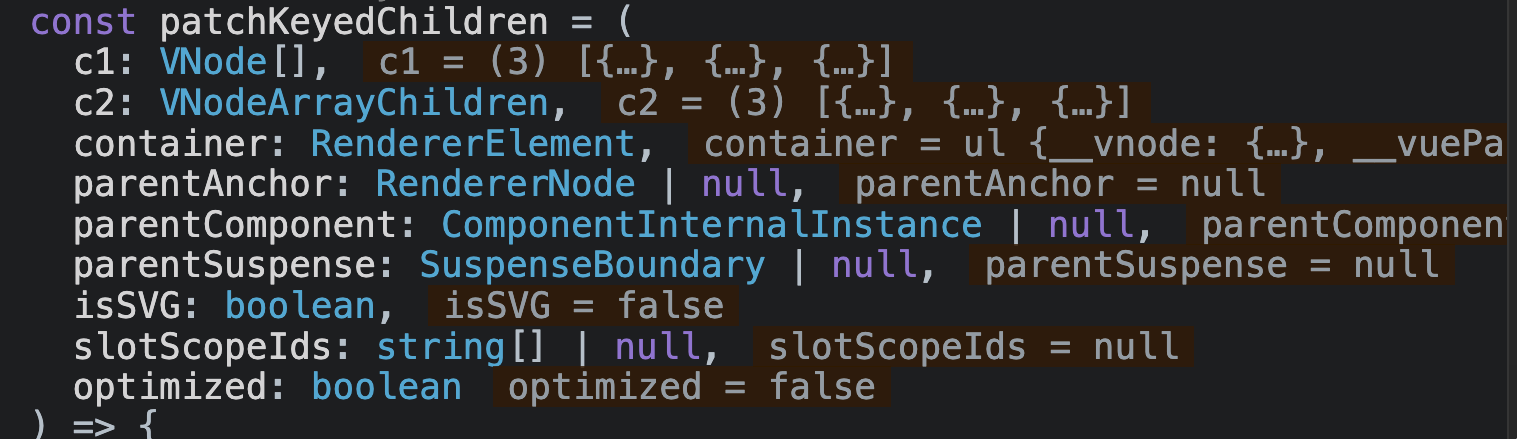
- 其中
c1表示为:旧的子节点,即:oldChildren c2表示为:新的子节点,即:newChildren
- 其中
执行
let i = 0,声明了一个 计数变量i,初始为0执行
const l2 = c2.length。此时的l2表示为 新的子节点的长度,即:newChildrenLength执行
let e1 = c1.length - 1。此时的e1表示为 旧的子节点最大(最后一个)下标,即:oldChildrenEnd执行
let e2 = l2 - 1。此时的e2表示为 **新的子节点最大(最后一个)下标,**即:newChildrenEnd进入第一个
while,此时因为不满足isSameVNodeType的场景,所以会直接 跳出 while进入 第二个 while,此时各变量的值为

执行
while循环:while (i <= e1 && i <= e2)第一次 进入
while循环:此时
n1的值为:jsh('li', { key: 3 }, 'c')此时
n2的值为:jsh('li', { key: 3 }, 'd')那么根据上一小节所说,我们知道,此时
isSameVNodeType(n1, n2)会被判定为true所以此时执行
patch方法,进行打补丁即可。最后执行:
e1--和e2--至此,第一次循环完成 (此时浏览器视图已经更新)
第二次 进入
while循环:- 根据刚才所知,此时的
n1和n2依然符合isSameVNodeType(n1, n2)的判定 - 所以,依然会执行
patch方法,进行打补丁。 - 最后执行:
e1--和e2-- - 至此,第二次循环完成
- 根据刚才所知,此时的
第三次 进入
while循环:根据刚才所知,此时的
n1和n2不再符合isSameVNodeType(n1, n2)的判定所以,会直接跳出循环
此时,各变量的值为:

三次循环全部完成,此时,我们查看浏览器,可以发现
children的 更新 操作 已经完成。后续的代码无需关心。
那么由以上可知:
vue的diff首先会 自前向后 和 自后向前,处理所有的 相同的VNode节点- 每次处理成功之后,会自减
e1和e2,表示:新、旧节点中已经处理完成节点(自后向前)
06:框架实现:场景二:自后向前的 diff 对比
那么明确好了自后向前的 diff 对比之后,接下来我们就可以直接进行对应的实现了:
- 在
patchKeyedChildren方法中,处理自后向前的场景:
// 2. 自后向前的 diff 对比。经过该循环之后,从后开始的相同 vnode 将被处理
while (i <= oldChildrenEnd && i <= newChildrenEnd) {
const oldVNode = oldChildren[oldChildrenEnd]
const newVNode = normalizeVNode(newChildren[newChildrenEnd])
if (isSameVNodeType(oldVNode, newVNode)) {
patch(oldVNode, newVNode, container, null)
} else {
break
}
oldChildrenEnd--
newChildrenEnd--
}创建测试实例 packages/vue/examples/runtime/render-element-diff-2.html:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'c'),
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 4
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'd')
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>07:源码阅读:场景三:新节点多余旧节点时的 diff 比对
以上两种场景,新节点数量和旧节点数量都是完全一致的。
但是我们也知道一旦产生更新,那么新旧节点的数量是可能会存在不一致的情况,具体的不一致情况会分为两种:
- 新节点的数量多于旧节点的数量
- 旧节点的数量多于新节点的数量
那么针对于这两种情况怎么进行处理呢?这就是我们接下来需要说的。
本小节,我们先来看一下 新节点的数量多于旧节点的数量 的场景,一旦出现这种场景,那么我们就需要 挂载多余的新节点。
但是新节点的数量多于旧节点的数量的场景下,依然可以被细分为两种具体的场景:
- 多出的新节点位于 尾部
- 多出的新节点位于 头部
明确好了以上内容之后,我们来看如下测试实例 packages/vue/examples/imooc/runtime/render-element-diff-3.html:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'c')
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>根据以上代码进入 debugger,忽略掉前两种场景,直接从第三种场景开始:
代码进入场景三
3. common sequence + mount,此时各参数的值为: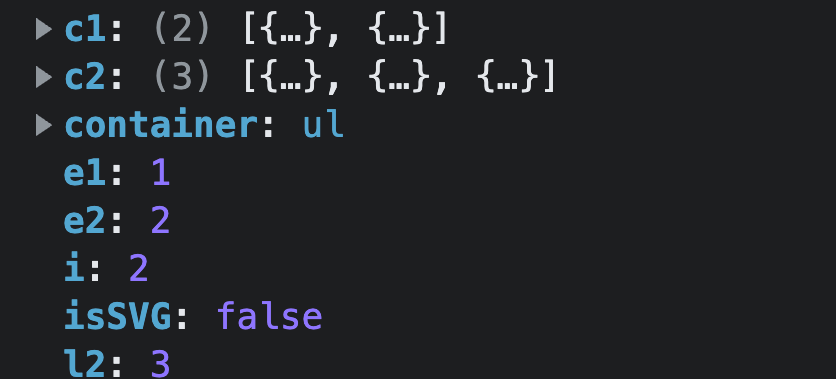
满足
if (i > e1)和if (i <= e2)的场景,进入if执行:
jsconst nextPos = e2 + 1 const anchor = nextPos < l2 ? (c2[nextPos] as VNode).el : parentAnchor- 这两行代码的目的是为了计算出
anchor,也就是新增节点插入的 锚点(位置)。 - 当前场景下
anchor = parentAnchor,即:使用父级的anchor
- 这两行代码的目的是为了计算出
执行
while (i <= e2),进入循环每次循环时,执行
patch方法,新增节点即可。最后执行
i++
以上逻辑为:多出的新节点位于 尾部 的场景。
那么接下来我们来看:多出的新节点位于 头部 的场景:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 3
}, 'c'),
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b')
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>根据以上代码,再次进入情景三:
代码进入场景三
3. common sequence + mount,此时各参数的值为: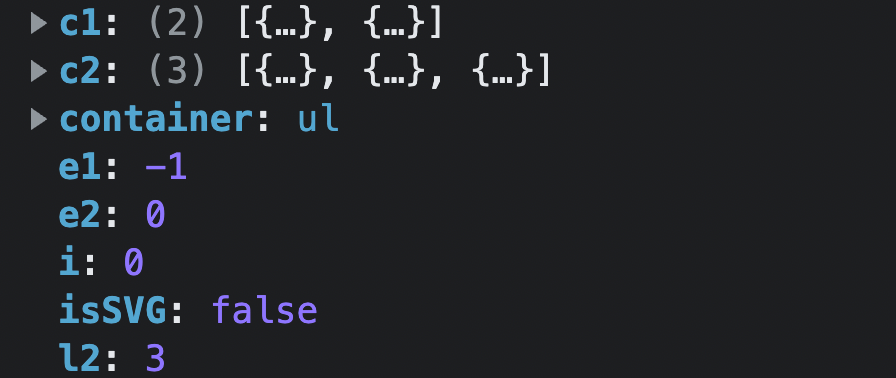
代码执行:
jsconst nextPos = e2 + 1 const anchor = nextPos < l2 ? (c2[nextPos] as VNode).el : parentAnchor- 此时
nextPos > l2,所以anchor的值为c2[1],即:新增的节点位于h('li', { key: 1 }, 'a')之前
- 此时
后续的代码执行略过
由以上代码可知:
- 对于 新节点多余旧节点 的场景具体可以在细分为两种情况:
- 多出的新节点位于 尾部
- 多出的新节点位于 头部
- 这两种情况下的区别在于:插入的位置不同
- 明确好插入的位置之后,直接通过
patch进行打补丁即可。
08:框架实现:场景三:新节点多余旧节点时的 diff 比对
根据上一小节的分析,我们可以直接在 packages/runtime-core/src/renderer.ts 中的 patchKeyedChildren 方法下,实现如下代码:
// 3. 新节点多余旧节点时的 diff 比对。
if (i > oldChildrenEnd) {
if (i <= newChildrenEnd) {
const nextPos = newChildrenEnd + 1
const anchor =
nextPos < newChildrenLength ? newChildren[nextPos].el : parentAnchor
while (i <= newChildrenEnd) {
patch(null, normalizeVNode(newChildren[i]), container, anchor)
i++
}
}
}创建对应测试实例 packages/vue/examples/runtime/render-element-diff-3.html:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 3
}, 'c'),
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>测试成功
09:源码阅读:场景四:旧节点多于新节点时的 diff 比对
接下来我们来看场景四 旧节点多于新节点时,根据场景三的经验,其实我们也可以明确,对于旧节点多于新节点时,对应的场景也可以细分为两种:
- 多出的旧节点位于 尾部
- 多出的旧节点位于 头部
那么我们先创建第一种场景下的测试实例 packages/vue/examples/imooc/runtime/render-element-diff-4.html :
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'c'),
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>跟踪代码,直接进入场景四即可:
代码进入场景四,此时的参数为:
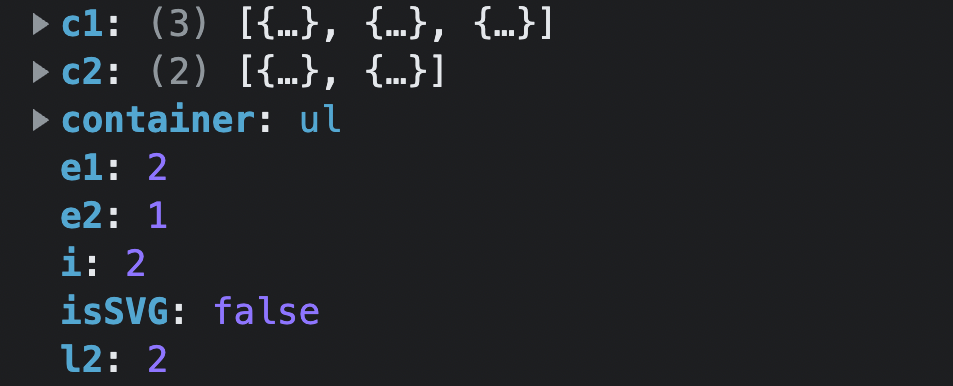
满足
i > e2满足
while循环i <= e1的判断- 直接执行
unmount(c1[i], parentComponent, parentSuspense, true)方法,对旧节点进行 卸载 操作 - 执行
i++
- 直接执行
以上代码比较简单,对于 多出的旧节点位于 头部 的场景,同样执行该逻辑。
由以上代码可知:
- 旧节点多于新节点时,整体的处理比较简单,只需要 卸载旧节点即可
10:框架实现:场景四:旧节点多于新节点时的 diff 比对
根据上一小节的分析,我们可以直接在 packages/runtime-core/src/renderer.ts 中的 patchKeyedChildren 方法下,实现如下代码:
// 4. 旧节点多与新节点时的 diff 比对。
else if (i > newChildrenEnd) {
while (i <= oldChildrenEnd) {
unmount(oldChildren[i])
i++
}
}可以创建如下测试实例 packages/vue/examples/runtime/render-element-diff-4.html:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 3
}, 'c'),
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>测试成功
11:局部总结:前四种 diff 场景的总结与乱序场景
那么到目前为止,我们已经完成了 4 种 diff 场景的对应处理,经过前面的学习我们可以知道,对于前四种 diff 场景而言,diff 的处理本质上是比较简单的:
- 自前向后的
diff对比:主要处理从前到后的相同VNode。例如:(a b) c对应(a b) d e - 自后向前的
diff对比:主要处理从后到前的相同VNode。例如:a (b c)对应d e (b c) - 新节点多余旧节点的
diff对比:主要处理新增节点。 - 旧节点多余新节点的
diff对比:主要处理删除节点。
但是仅靠前四种场景的话,那么是无法满足实际开发中的所有更新逻辑的。所以我们还需要最关键的一种场景需要处理,那就是 乱序场景。
那么什么情况下我们需要乱序场景呢?
我们来看以下的 diff 场景:
详见:
PPT -图谱

那么经过以上的 diff 处理之后,我们就只剩下中间三个节点的对应处理,那么中间三个的 diff 处理逻辑就是最后一种场景 乱序 的处理逻辑。
那么这种乱序具体是怎么进行的呢?我们继续来往下看~~
12:前置知识:场景五:最长递增子序列
在场景五的 diff 中,vue 使用了 最长递增子序列 这样的一个概念,所以想要更好地理解场景五,那么我们需要先搞明白,两个问题:
- 什么是最长递增子序列?
- 最长递增子序列在
diff中的作用是什么?
什么是最长递增子序列
在一个给定的数值序列中,找到一个子序列,使得这个子序列元素的数值依次递增,并且这个子序列的长度尽可能地大。
只看概念可能难以理解,我们来看一个具体的例子。
假设,我们现在有一个这样两组节点:
旧节点:1,2,3,4,5,6
新节点:1,3,2,4,6,5我们可以根据 新节点 生成 递增子序列(非最长)(注意:并不是惟一的),其结果为:
1、3、61、2、4、6- …
最长递增子序列在 diff 中的作用是什么
那么现在我们成功得到了 递增子序列,那么下面我们来看,这两个递增子序列在我们接下来的 diff 中起到了什么作用。
根据我们之前的四种场景可知,所谓的 diff,其实说白了就是对 一组节点 进行 添加、删除、打补丁 的对应操作。那么除了以上三种操作之外,其实还有最后一种操作方式,那就是 移动。
对于以上的节点对比而言,如果我们想要把 旧节点转化为新节点,那么将要涉及到节点的 移动,所以问题的重点是:如何进行移动。
大家看到这里可以,先暂停,想一下:如果是你的话,那么你会如何移动节点,才能以最少的移动次数,完成更新?
那么接下来,我们来分析一下移动的策略,整个移动根据递增子序列的不同,将拥有两种移动策略:
1、3、6递增序列下:- 因为
1、3、6的递增已确认,所以它们三个是不需要移动的,那么我们所需要移动的节点无非就是 三 个2、4、5。 - 所以我们需要经过 三次 移动
- 因为
1、2、4、6递增序列下:- 因为
1、2、4、6的递增已确认,所以它们四个是不需要移动的,那么我们所需要移动的节点无非就是 两个3、5。 - 所以我们需要经过 两次 移动
- 因为
所以由以上分析,我们可知:最长递增子序列的确定,可以帮助我们减少移动的次数
所以,当我们需要进行节点移动时,移动需要事先构建出最长递增子序列,以保证我们的移动方案。
13:源码逻辑:场景五:求解最长递增子序列
我们查看 packages/runtime-core/src/renderer.ts 中的 2410 行代码,可以看到存在一个 getSequence 的函数,这个函数的作用就是用来 获取最长递增子序列的下标(必须要获取下标才知道当前元素所处的位置)。
该函数算法来自于 维基百科(贪心 + 二分查找),该方法的执行逻辑,如 PPT 所示:
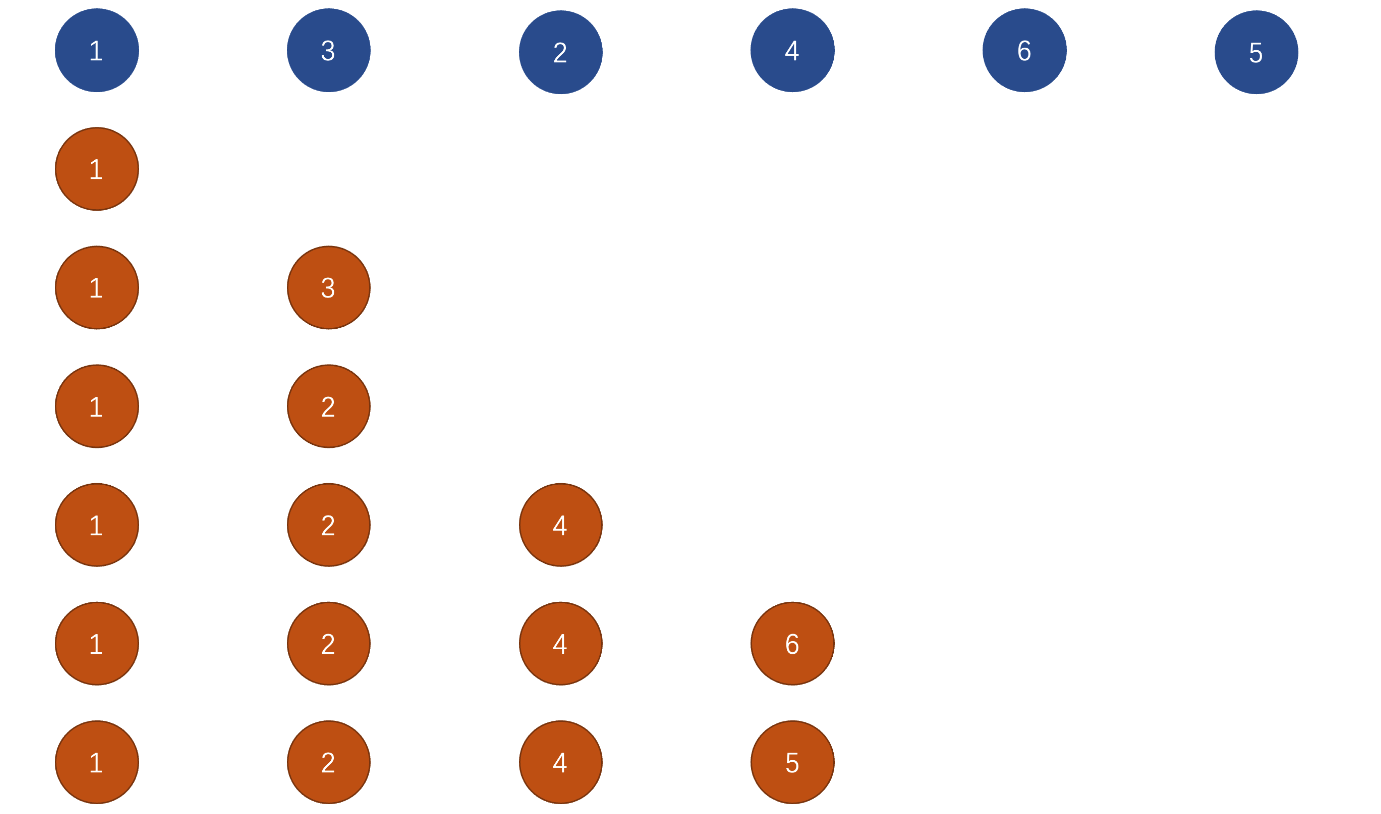
我们复制了 vue 3 中 getSequence 的所有代码,并为其加入了详细的备注,如下:
/**
* 获取最长递增子序列下标
* 维基百科:https://en.wikipedia.org/wiki/Longest_increasing_subsequence
* 百度百科:https://baike.baidu.com/item/%E6%9C%80%E9%95%BF%E9%80%92%E5%A2%9E%E5%AD%90%E5%BA%8F%E5%88%97/22828111
*/
function getSequence(arr) {
// 获取一个数组浅拷贝。注意 p 的元素改变并不会影响 arr
// p 是一个最终的回溯数组,它会在最终的 result 回溯中被使用
// 它会在每次 result 发生变化时,记录 result 更新前最后一个索引的值
const p = arr.slice()
// 定义返回值(最长递增子序列下标),因为下标从 0 开始,所以它的初始值为 0
const result = [0]
let i, j, u, v, c
// 当前数组的长度
const len = arr.length
// 对数组中所有的元素进行 for 循环处理,i = 下标
for (i = 0; i < len; i++) {
// 根据下标获取当前对应元素
const arrI = arr[i]
//
if (arrI !== 0) {
// 获取 result 中的最后一个元素,即:当前 result 中保存的最大值的下标
j = result[result.length - 1]
// arr[j] = 当前 result 中所保存的最大值
// arrI = 当前值
// 如果 arr[j] < arrI 。那么就证明,当前存在更大的序列,那么该下标就需要被放入到 result 的最后位置
if (arr[j] < arrI) {
p[i] = j
// 把当前的下标 i 放入到 result 的最后位置
result.push(i)
continue
}
// 不满足 arr[j] < arrI 的条件,就证明目前 result 中的最后位置保存着更大的数值的下标。
// 但是这个下标并不一定是一个递增的序列,比如: [1, 3] 和 [1, 2]
// 所以我们还需要确定当前的序列是递增的。
// 计算方式就是通过:二分查找来进行的
// 初始下标
u = 0
// 最终下标
v = result.length - 1
// 只有初始下标 < 最终下标时才需要计算
while (u < v) {
// (u + v) 转化为 32 位 2 进制,右移 1 位 === 取中间位置(向下取整)例如:8 >> 1 = 4; 9 >> 1 = 4; 5 >> 1 = 2
// https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operators/Right_shift
// c 表示中间位。即:初始下标 + 最终下标 / 2 (向下取整)
c = (u + v) >> 1
// 从 result 中根据 c(中间位),取出中间位的下标。
// 然后利用中间位的下标,从 arr 中取出对应的值。
// 即:arr[result[c]] = result 中间位的值
// 如果:result 中间位的值 < arrI,则 u(初始下标)= 中间位 + 1。即:从中间向右移动一位,作为初始下标。 (下次直接从中间开始,往后计算即可)
if (arr[result[c]] < arrI) {
u = c + 1
} else {
// 否则,则 v(最终下标) = 中间位。即:下次直接从 0 开始,计算到中间位置 即可。
v = c
}
}
// 最终,经过 while 的二分运算可以计算出:目标下标位 u
// 利用 u 从 result 中获取下标,然后拿到 arr 中对应的值:arr[result[u]]
// 如果:arr[result[u]] > arrI 的,则证明当前 result 中存在的下标 《不是》 递增序列,则需要进行替换
if (arrI < arr[result[u]]) {
if (u > 0) {
p[i] = result[u - 1]
}
// 进行替换,替换为递增序列
result[u] = i
}
}
}
// 重新定义 u。此时:u = result 的长度
u = result.length
// 重新定义 v。此时 v = result 的最后一个元素
v = result[u - 1]
// 自后向前处理 result,利用 p 中所保存的索引值,进行最后的一次回溯
while (u-- > 0) {
result[u] = v
v = p[v]
}
return result
}我们可以通过以上代码,对 getSequence([1, 3, 2, 4, 6, 5]) 进行测试,debugger 代码的执行逻辑(具体请查看视频),从而明确当前算法的逻辑。
明确以上逻辑之后,我们把该代码逻辑,直接复制到 vue-next-mini 中即可。
14:源码阅读:场景五:乱序下的 diff 比对
那么到目前为止,我们已经明确了:
diff指的就是:添加、删除、打补丁、移动 这四个行为- 最长递增子序列 是什么,如何计算的,以及在
diff中的作用 - 场景五的乱序,是最复杂的场景,将会涉及到 添加、删除、打补丁、移动 这些所有场景。
那么明确好了以上内容之后,我们先来看对应场景五的测试实例 packages/vue/examples/imooc/runtime/render-element-diff-5.html:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'c'),
h('li', {
key: 4
}, 'd'),
h('li', {
key: 5
}, 'e')
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 1
}, 'new-a'),
h('li', {
key: 3
}, 'new-c'),
h('li', {
key: 2
}, 'new-b'),
h('li', {
key: 6
}, 'new-f'),
h('li', {
key: 5
}, 'new-e'),
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>该测试实例对应的节点渲染图为:

运行该测试实例,我们来跟踪场景五的逻辑:
// 5. unknown sequence
// [i ... e1 + 1]: a b [c d e] f g
// [i ... e2 + 1]: a b [e d c h] f g
// i = 2, e1 = 4, e2 = 5
else {
// 旧子节点的开始索引:oldChildrenStart
const s1 = i
// 新子节点的开始索引:newChildrenStart
const s2 = i
// 5.1 创建一个 <key(新节点的 key):index(新节点的位置)> 的 Map 对象 keyToNewIndexMap。通过该对象可知:新的 child(根据 key 判断指定 child) 更新后的位置(根据对应的 index 判断)在哪里
const keyToNewIndexMap: Map<string | number | symbol, number> = new Map()
// 通过循环为 keyToNewIndexMap 填充值(s2 = newChildrenStart; e2 = newChildrenEnd)
for (i = s2; i <= e2; i++) {
// 从 newChildren 中根据开始索引获取每一个 child(c2 = newChildren)
const nextChild = (c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i]))
// child 必须存在 key(这也是为什么 v-for 必须要有 key 的原因)
if (nextChild.key != null) {
// key 不可以重复,否则你将会得到一个错误
if (__DEV__ && keyToNewIndexMap.has(nextChild.key)) {
warn(
`Duplicate keys found during update:`,
JSON.stringify(nextChild.key),
`Make sure keys are unique.`
)
}
// 把 key 和 对应的索引,放到 keyToNewIndexMap 对象中
keyToNewIndexMap.set(nextChild.key, i)
}
}
// 5.2 循环 oldChildren ,并尝试进行 patch(打补丁)或 unmount(删除)旧节点
let j
// 记录已经修复的新节点数量
let patched = 0
// 新节点待修补的数量 = newChildrenEnd - newChildrenStart + 1
const toBePatched = e2 - s2 + 1
// 标记位:节点是否需要移动
let moved = false
// 配合 moved 进行使用,它始终保存当前最大的 index 值
let maxNewIndexSoFar = 0
// 创建一个 Array 的对象,用来确定最长递增子序列。它的下标表示:《新节点的下标(newIndex),不计算已处理的节点。即:n-c 被认为是 0》,元素表示:《对应旧节点的下标(oldIndex),永远 +1》
// 但是,需要特别注意的是:oldIndex 的值应该永远 +1 ( 因为 0 代表了特殊含义,他表示《新节点没有找到对应的旧节点,此时需要新增新节点》)。即:旧节点下标为 0, 但是记录时会被记录为 1
const newIndexToOldIndexMap = new Array(toBePatched)
// 遍历 toBePatched ,为 newIndexToOldIndexMap 进行初始化,初始化时,所有的元素为 0
for (i = 0; i < toBePatched; i++) newIndexToOldIndexMap[i] = 0
// 遍历 oldChildren(s1 = oldChildrenStart; e1 = oldChildrenEnd),获取旧节点(c1 = oldChildren),如果当前 已经处理的节点数量 > 待处理的节点数量,那么就证明:《所有的节点都已经更新完成,剩余的旧节点全部删除即可》
for (i = s1; i <= e1; i++) {
// 获取旧节点(c1 = oldChildren)
const prevChild = c1[i]
// 如果当前 已经处理的节点数量 > 待处理的节点数量,那么就证明:《所有的节点都已经更新完成,剩余的旧节点全部删除即可》
if (patched >= toBePatched) {
// 所有的节点都已经更新完成,剩余的旧节点全部删除即可
unmount(prevChild, parentComponent, parentSuspense, true)
continue
}
// 新节点需要存在的位置,需要根据旧节点来进行寻找(包含已处理的节点。即:n-c 被认为是 1)
let newIndex
// 旧节点的 key 存在时
if (prevChild.key != null) {
// 根据旧节点的 key,从 keyToNewIndexMap 中可以获取到新节点对应的位置
newIndex = keyToNewIndexMap.get(prevChild.key)
} else {
// 旧节点的 key 不存在(无 key 节点)
// 那么我们就遍历所有的新节点(s2 = newChildrenStart; e2 = newChildrenEnd),找到《没有找到对应旧节点的新节点,并且该新节点可以和旧节点匹配》(s2 = newChildrenStart; c2 = newChildren),如果能找到,那么 newIndex = 该新节点索引
for (j = s2; j <= e2; j++) {
// 找到《没有找到对应旧节点的新节点,并且该新节点可以和旧节点匹配》(s2 = newChildrenStart; c2 = newChildren)
if (
newIndexToOldIndexMap[j - s2] === 0 &&
isSameVNodeType(prevChild, c2[j] as VNode)
) {
// 如果能找到,那么 newIndex = 该新节点索引
newIndex = j
break
}
}
}
// 最终没有找到新节点的索引,则证明:当前旧节点没有对应的新节点
if (newIndex === undefined) {
// 此时,直接删除即可
unmount(prevChild, parentComponent, parentSuspense, true)
}
// 没有进入 if,则表示:当前旧节点找到了对应的新节点,那么接下来就是要判断对于该新节点而言,是要 patch(打补丁)还是 move(移动)
else {
// 为 newIndexToOldIndexMap 填充值:下标表示:《新节点的下标(newIndex),不计算已处理的节点。即:n-c 被认为是 0》,元素表示:《对应旧节点的下标(oldIndex),永远 +1》
// 因为 newIndex 包含已处理的节点,所以需要减去 s2(s2 = newChildrenStart)表示:不计算已处理的节点
newIndexToOldIndexMap[newIndex - s2] = i + 1
// maxNewIndexSoFar 会存储当前最大的 newIndex,它应该是一个递增的,如果没有递增,则证明有节点需要移动
if (newIndex >= maxNewIndexSoFar) {
// 持续递增
maxNewIndexSoFar = newIndex
} else {
// 没有递增,则需要移动,moved = true
moved = true
}
// 打补丁
patch(
prevChild,
c2[newIndex] as VNode,
container,
null,
parentComponent,
parentSuspense,
isSVG,
slotScopeIds,
optimized
)
// 自增已处理的节点数量
patched++
}
}
// 5.3 针对移动和挂载的处理
// 仅当节点需要移动的时候,我们才需要生成最长递增子序列,否则只需要有一个空数组即可
const increasingNewIndexSequence = moved
? getSequence(newIndexToOldIndexMap)
: EMPTY_ARR
// j >= 0 表示:初始值为 最长递增子序列的最后下标
// j < 0 表示:《不存在》最长递增子序列。
j = increasingNewIndexSequence.length - 1
// 倒序循环,以便我们可以使用最后修补的节点作为锚点
for (i = toBePatched - 1; i >= 0; i--) {
// nextIndex(需要更新的新节点下标) = newChildrenStart + i
const nextIndex = s2 + i
// 根据 nextIndex 拿到要处理的 新节点
const nextChild = c2[nextIndex] as VNode
// 获取锚点(是否超过了最长长度)
const anchor =
nextIndex + 1 < l2 ? (c2[nextIndex + 1] as VNode).el : parentAnchor
// 如果 newIndexToOldIndexMap 中保存的 value = 0,则表示:新节点没有用对应的旧节点,此时需要挂载新节点
if (newIndexToOldIndexMap[i] === 0) {
// 挂载新节点
patch(
null,
nextChild,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
slotScopeIds,
optimized
)
}
// moved 为 true,表示需要移动
else if (moved) {
// j < 0 表示:不存在 最长递增子序列
// i !== increasingNewIndexSequence[j] 表示:当前节点不在最后位置
// 那么此时就需要 move (移动)
if (j < 0 || i !== increasingNewIndexSequence[j]) {
move(nextChild, container, anchor, MoveType.REORDER)
} else {
// j 随着循环递减
j--
}
}
}
}由以上代码可知:
- 乱序下的
diff是 最复杂 的一块场景 - 它的主要逻辑分为三大步:
- 创建一个
<key(新节点的 key):index(新节点的位置)>的Map对象keyToNewIndexMap。通过该对象可知:新的child(根据key判断指定child) 更新后的位置(根据对应的index判断)在哪里 - 循环
oldChildren,并尝试进行patch(打补丁)或unmount(删除)旧节点 - 处理 移动和挂载
- 创建一个
15:框架实现:场景五:乱序下的 diff 比对
那么明确好了对应的概念之后,我们下面就可以实现对应逻辑了,因为咱们要实现的代码,本质上和 vue 中的代码一致,所以我们没有必要再重头写一遍了,我们只需要复制 vue 中的源码,然后修改一下变量名 即可
在
patchKeyedChildren中,添加场景五乱序逻辑:js// 5. 乱序的 diff 比对 else { const oldStartIndex = i const newStartIndex = i const keyToNewIndexMap = new Map() for (i = newStartIndex; i <= newChildrenEnd; i++) { const nextChild = normalizeVNode(newChildren[i]) if (nextChild.key != null) { keyToNewIndexMap.set(nextChild.key, i) } } let j let patched = 0 const toBePatched = newChildrenEnd - newStartIndex + 1 let moved = false let maxNewIndexSoFar = 0 const newIndexToOldIndexMap = new Array(toBePatched) for (i = 0; i < toBePatched; i++) newIndexToOldIndexMap[i] = 0 for (i = oldStartIndex; i <= oldChildrenEnd; i++) { const prevChild = oldChildren[i] if (patched >= toBePatched) { unmount(prevChild) continue } let newIndex if (prevChild.key != null) { newIndex = keyToNewIndexMap.get(prevChild.key) } if (newIndex === undefined) { unmount(prevChild) } else { newIndexToOldIndexMap[newIndex - newStartIndex] = i + 1 if (newIndex >= maxNewIndexSoFar) { maxNewIndexSoFar = newIndex } else { moved = true } patch(prevChild, newChildren[newIndex], container, null) patched++ } } const increasingNewIndexSequence = moved ? getSequence(newIndexToOldIndexMap) : [] j = increasingNewIndexSequence.length - 1 for (i = toBePatched - 1; i >= 0; i--) { const nextIndex = newStartIndex + i const nextChild = newChildren[nextIndex] const anchor = nextIndex + 1 < newChildrenLength ? newChildren[nextIndex + 1].el : parentAnchor if (newIndexToOldIndexMap[i] === 0) { patch(null, nextChild, container, anchor) } else if (moved) { if (j < 0 || i !== increasingNewIndexSequence[j]) { move(nextChild, container, anchor) } else { j-- } } } }新增
move方法:js/** * 移动节点到指定位置 */ const move = (vnode, container, anchor) => { const { el } = vnode hostInsert(el!, container, anchor) }
至此,场景五的逻辑完成。
可以创建对应测试实例 packages/vue/examples/imooc/runtime/render-element-diff-5.html:
<script>
const { h, render } = Vue
const vnode = h('ul', [
h('li', {
key: 1
}, 'a'),
h('li', {
key: 2
}, 'b'),
h('li', {
key: 3
}, 'c'),
h('li', {
key: 4
}, 'd'),
h('li', {
key: 5
}, 'e')
])
// 挂载
render(vnode, document.querySelector('#app'))
// 延迟两秒,生成新的 vnode,进行更新操作
setTimeout(() => {
const vnode2 = h('ul', [
h('li', {
key: 1
}, 'new-a'),
h('li', {
key: 3
}, 'new-c'),
h('li', {
key: 2
}, 'new-b'),
h('li', {
key: 6
}, 'new-f'),
h('li', {
key: 5
}, 'new-e'),
])
render(vnode2, document.querySelector('#app'))
}, 2000);
</script>测试成功
16:总结
那么到这里我们就已经完成了 diff 算法的逻辑。
整个的 diff 就分成 5 种场景,前四种场景相对而言,还比较简单。最复杂的就是第五种,乱序的场景。
整个 diff 中,涉及到了很多的算法,可能还有很多我们之前不太了解的一些概念,比如:最长递增子序列。
那么 diff 完成之后,也标记着我们整个的 runtime 就已经全部讲解完成了。
那么在这里我们把整个 runtime 总结一下,对于 runtime 而言:
- 首先我们讲解了
dom、节点、节点树和虚拟DOM,虚拟节点之间的概念。 - 然后我们说明了
render函数和h函数各自的作用。我们知道h函数可以得到一个vnode,而render函数可以渲染一个vnode - 接下来我们讲解了挂载、更新、卸载,这三组概念。也知道了针对于不同的
vnode节点,那么他们的挂载、更新、卸载方式也都是不同的。 - 下面我们讲解了组件,我们知道组件本质上是一个对象(或函数),组件的挂载本质上是
render函数的挂载。 - 组件内部维护了一个
effect对象,以达到响应性渲染的效果。 - 而针对于
setup函数而言,它在实现上反而更加简单,因为我们不需要改变this指向了。 - 结合所学,新旧节点的所有挂载和更新情况,可以被分为九种场景:
- 旧节点为纯文本时:
- 新节点为纯文本:执行文本替换操作
- 新节点为空:删除旧节点
- 新节点为数组:清空文本,添加多个新节点
- 旧节点为空时:
- 新节点为纯文本:添加新节点
- 新节点为空:不做任何事情
- 新节点为数组时:添加多个新节点
- 旧节点是数组时:
- 新节点为纯文本:删除所有旧节点,添加新节点
- 新节点为空:删除所有旧节点
- 新节点为数组时:进行
diff操作
- 旧节点为纯文本时:
- 最后的
diff分为5种场景,最后一种场景还是比较复杂的。
那么从下一章开始,我们就要进入到 编译器 compiler 模块的学习了,大家准备好了~~~